(13A) Exploring the Table Panel heat map
Expression Viewer
i.When a gene expression matrix is provided as input to EnrichmentMap, we can study the expression pattern of the genes included in enriched pathways.
- Click on either an individual node -
- or a group of nodes -
to generate a gene expression heat map that will appear in the Heat Map tab of the Table Panel.
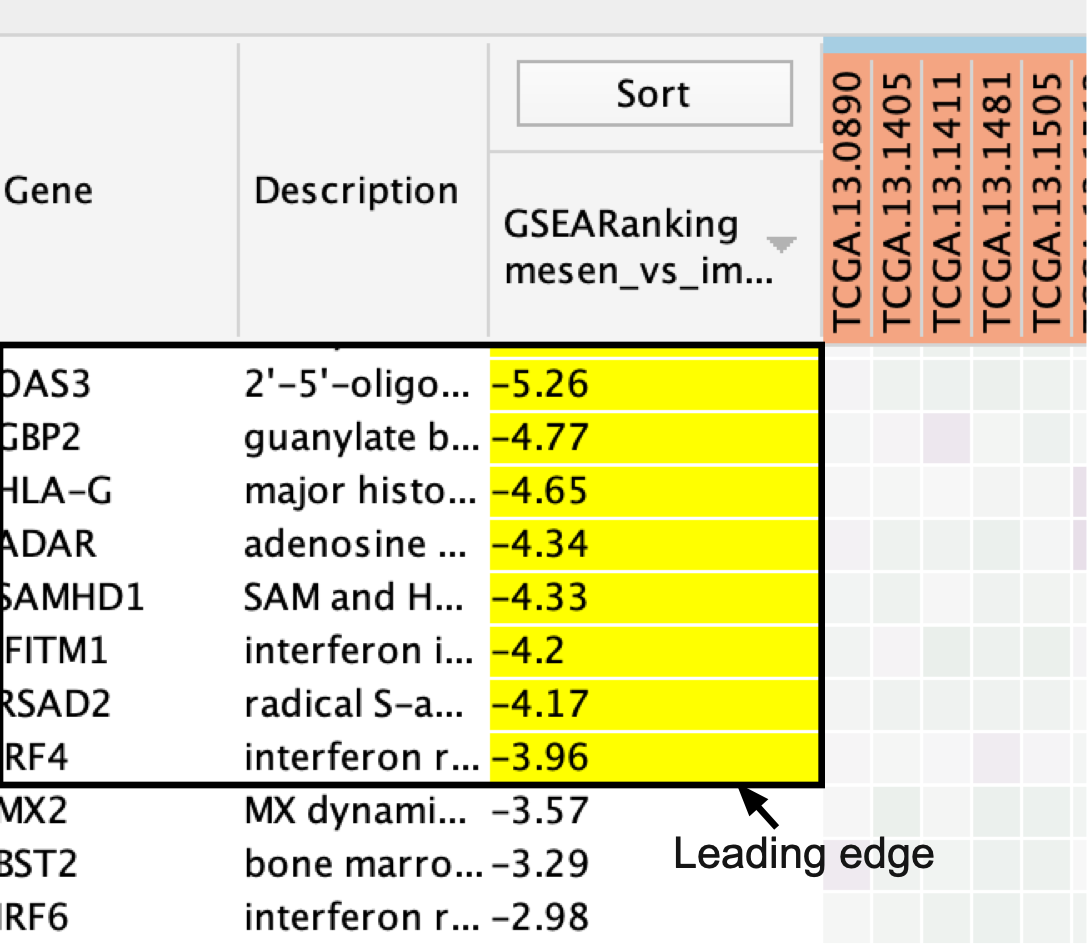
- If the analysis is based on GSEA results and a rank file is supplied, the ‘leading edge’ genes will be highlighted in yellow for individual node selections.
- Several options for heat map visualization are available.
If no expression file is provided to EnrichmentMap as input, it will automatically create a dummy expression file in which any gene found in the enrichment file will be given a placeholder expression value of 0.25, and any gene found in a pathway but not found in the enrichment results file will be assigned a placeholder expression value of ‘NA’ (not applicable). Therefore, clicking on any node in the enrichment map will show the genes used for the analysis as well as genes in the pathway that are not part of the query set.
Sorting options
- Adjust the Sort option.
- Sorting options include:
- hierarchical clustering,
- ranks or
- clicking on any of the column headers in heatmap will sort by that column
- To change the sorting option:
- click on the Sort button visible in the top left corner of the heat map table.
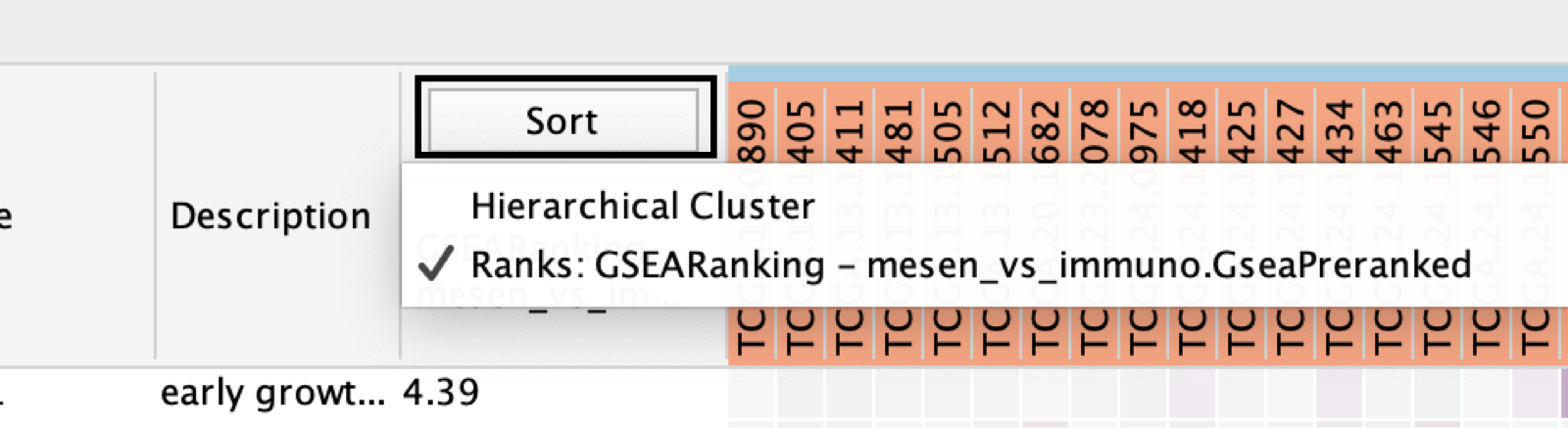
- By default, the heat map is sorted by ranks if a rank file is supplied.
- In the absence of a rank file, no sort is applied.
- Additional rank files can be uploaded for comparison through the Settings menu located at the top right corner in the Heat Map panel.
- Choosing which rank file to sort from can be done by clicking on the Sort button and selecting the rank file by name.
- Click the arrow next to the currently sorted column to invert the sort order.
- Click any of the column names to sort the selected column.
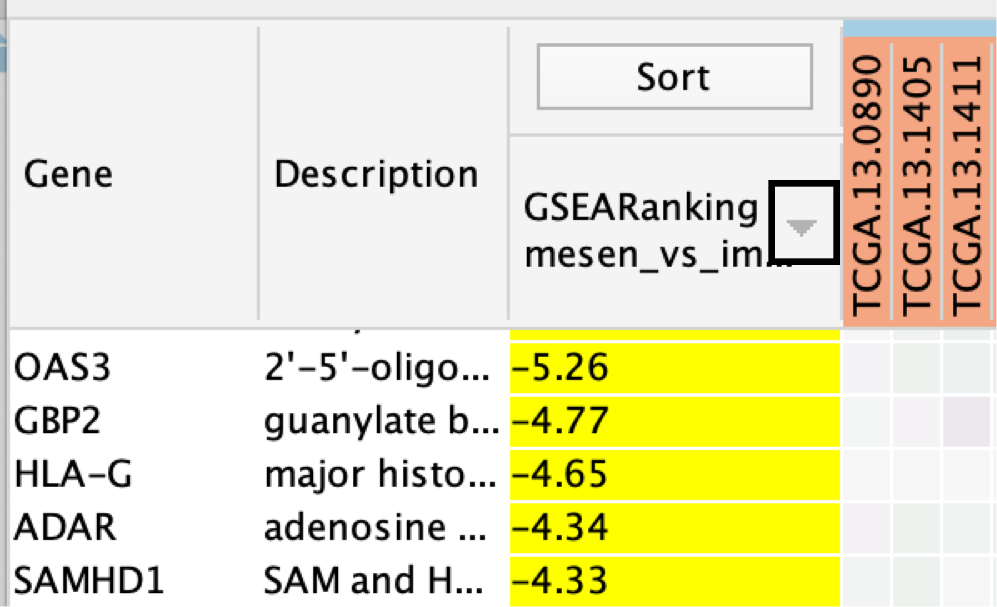
User does not know which sort option to choose
In the case of multiple conditions or conditions with variable expression profiles (e.g., cancer patient samples), hierarchical clustering tends to generate a more informative visualization
Gene Options
- Define Genes you wish to visualize in the heat map
- Data can be viewed for all genes contained in the selected nodes (union of nodes) or
- just for the genes common to selected nodes (intersection of nodes). By default,
- all genes are shown.

Expression data transformations
- Change the Expressions value visualization depending on your data type
- Data can be viewed:
- as they were loaded (Values),
- as row-normalized, in which case the row mean is subtracted from each value and then divided by the row’s standard deviation (Row Norm),
- or as log-transformed (Log).
- By default, set to (Values).

- Compress heat map columns
- By default, all expression values are visible as individual columns in the heat map for expression sets with <50 samples.
- It is possible to compress the data into a single column by selecting one of the aggregation methods:
- Dataset - Median,
- Dataset - Max (maximum) or
- Dataset - Min (minimum) —listed under Compress.
- If a CLS file has been uploaded, the expression set can be compressed using one column per defined sample group using the Class option.
- Class - Median,
- Class - Max (maximum) or
- Class - Min (minimum)
- Dataset - Median,
- Dataset - Max (maximum) or
- Dataset - Min (minimum)
If the expression matrix contains ≥50 samples, EnrichmentMap will automatically compress the values to their Dataset median value by default.

- Check Values to show the expression numerical values in addition to the heat map color scale.
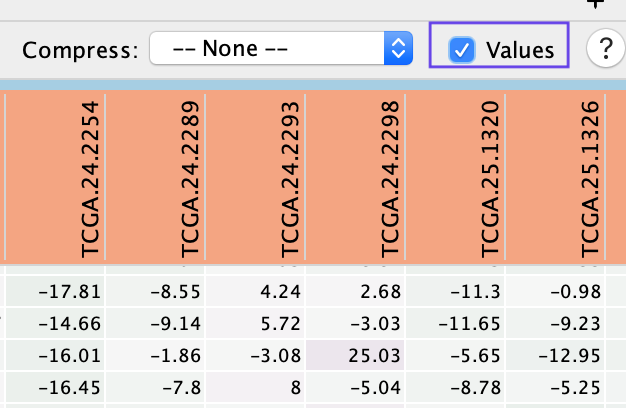
Additional Functions
- Perform additional fine-tuning of the heat map using the Settings panel, accessed by clicking on the menu icon
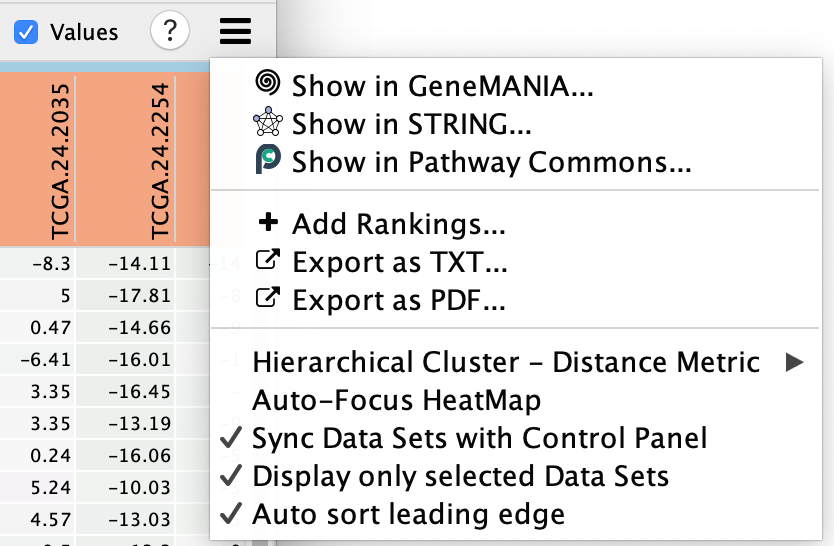
- This includes functionality to:
- Show in GeneMANIA... - Use the genes in the heatmap and search GeneMANIA(Warde-Farley et al. 2010).
- Show in STRING ... - Use the genes in the heatmap and search STRING.
- Show in Pathway Commons... - Use the genes in the heatmap and search Pathway Commons.
- Add Rankings - add new ranking files,
- Export as TXT... - export the heat map data as a tab-delimited text file
- Export as PDF... - export the heat map data as a PDF image,
- change the distance metric for hierarchical clustering,
- Auto-focus HeatMap - turn on the node table heat map auto focus.
- Sync Data Sets with Control Panel
- Display only selected Data Sets - when using multiple datasets there can be many expression files. By default the heat map will only show the expression files of the selected dataset but if you would like to see them all then you can change this setting.
- Auto Select leading edge
Genes are sorted using the GSEA rank file, highlighting the leading edge in yellow. All genes contained in selected nodes are shown, expression values are row-normalized, no compression is applied and individual expression numerical values are not shown. Column headings are colored according to sample phenotype. Red color refers to the first phenotype (mesenchymal), and blue to the second phenotype (immunoreactive).
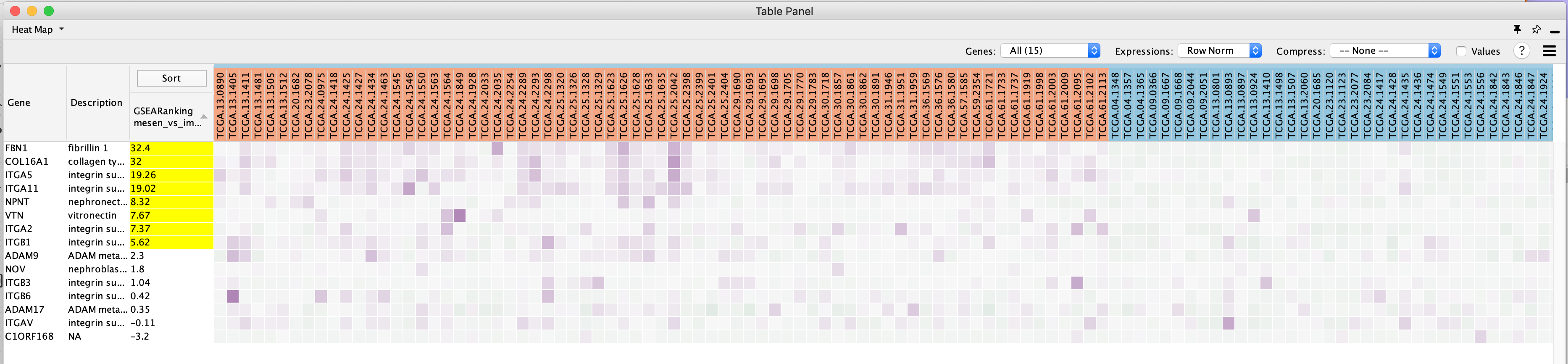
Heat map column names are not colored by dataset
If the heat map columns are not colored for a GSEA analysis, make sure the phenotype names specified in the EnrichmentMap input panel here:

match the class names specified in the class file Supplementary_Table7_TCGA_OV_RNAseq_classes.cls.
Export Results
- The heat map can be exported to a text file for further analysis: click on the Settings icon of the heat map and select Export as TXT.
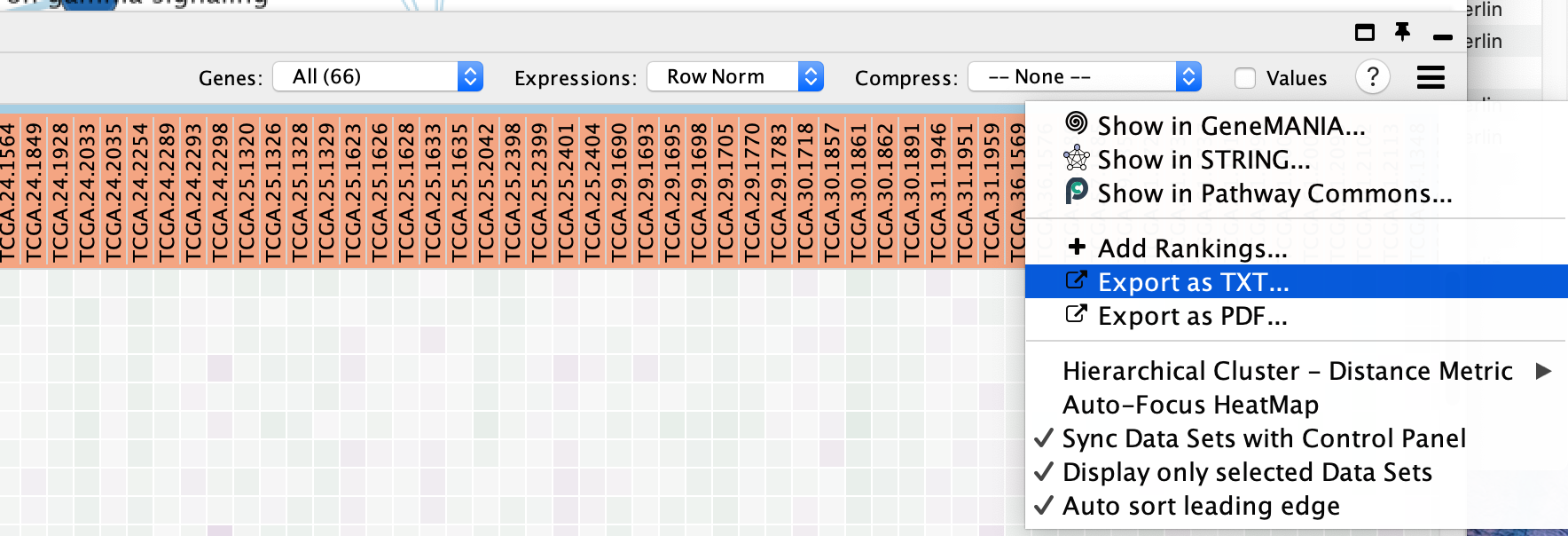
- If only an individual node is selected, a dialog will offer to export the Leading edge only for GSEA analysis. If selected, only the highlighted genes will be exported; otherwise, the entire set of genes is saved.
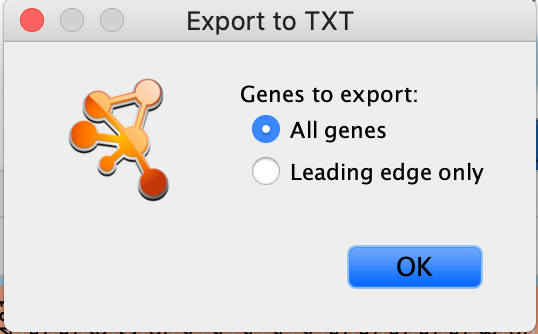
The option to save only leading-edge genes is not available
- Selection includes more than one node or dataset contains no leading-edge information (i.e., was not built from GSEA results
- The leading edge is available only for GSEA analyses. The option will appear only if the enrichment map was built with GSEA results and a rank file was specified
- Specify the file name and location and click Save.
References
Warde-Farley, David, Sylva L Donaldson, Ovi Comes, Khalid Zuberi, Rashad Badrawi, Pauline Chao, Max Franz, et al. 2010. “The Genemania Prediction Server: Biological Network Integration for Gene Prioritization and Predicting Gene Function.” Nucleic Acids Research 38 (suppl_2). Oxford University Press: W214–W220.