Module 6 lab 3: cellPhoneDB
This work is licensed under a Creative Commons Attribution-ShareAlike 3.0 Unported License. This means that you are able to copy, share and modify the work, as long as the result is distributed under the same license.
Cell-Cell communication in scRNA: CellPhoneDB
- Learning objectives: learn how to take the result of CellPhoneDB and build a Cytoscape network.
Presentation
CellPhoneDB is a repository of ligands, receptors and their interactions. CellPhoneDB database takes into account the subunit architecture of both ligands and receptors, representing heteromeric complexes accurately. A statistical framework is integrated that predicts enriched cellular interactions between two cell types from single-cell transcriptomics data
CellPhoneDB database: public resources to annotate receptors and ligands, as well as manual curation of specific families of proteins involved in cell–cell communication
possibility of using own list of ligand–receptor interactions
Method
CellPhoneDB input data consist of a scRNA-seq counts file and cell-type annotation.
Enriched receptor–ligand interactions between two cell types are derived on the basis of expression of a receptor by one cell type and a ligand by another cell type. The member of the complex with the minimum average expression is considered for the subsequent statistical analysis.
A null distribution of the mean of the average ligand and receptor expression in the interacting clusters is generated by randomly permuting the cluster labels of all cells.
The p value for the likelihood of cell-type specificity of a given receptor–ligand complex is calculated on the basis of the proportion of the means that are as high as or higher than the actual mean (=empirical pvalue).
Ligand–receptor pairs are ranked on the basis of their total number of significant p values across the cell populations.
Summary of the steps:
The dataset consists of ~25k peripheral blood mononuclear cell (PBMCs) from 8 pooled lupus patients, each before and after IFN-β stimulation.
Preparing the scRNA using your method of choice: Standard preprocessing consists of filtering out bad quality cells, normalizing, clustering and annotating the cells. In this case, the cells are different types of blood cells and they were annotated using specific cell markers for these different cell types.
Let’s explore the UMAP:
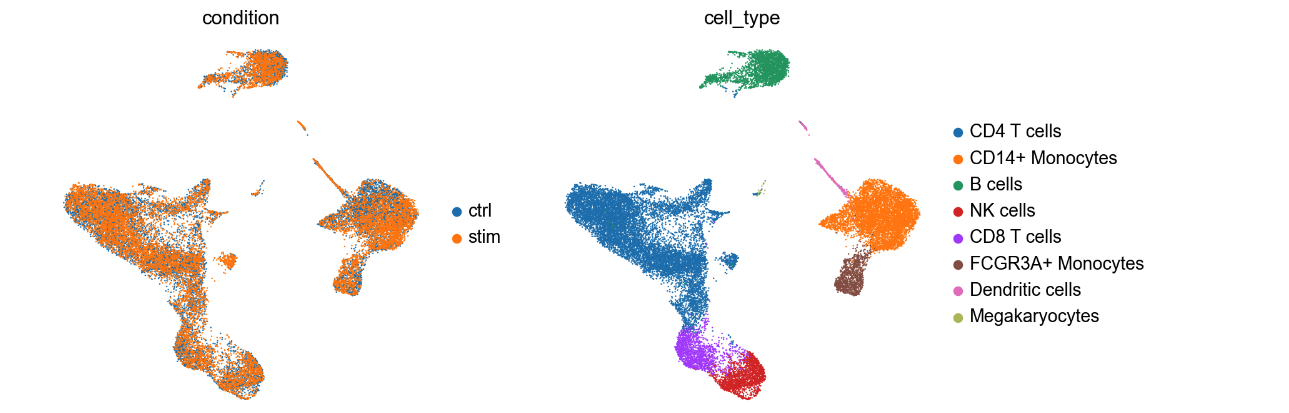
UMAP (Uniform Manifold Approximation and Projection) is frequently used in scRNA to display the data in 2 dimensions. The UMAP on the right displays all the cells that are clustered based on cell types. It helps visualizing groups of cells that are close together. The colors on the UMAP represent clusters of cells that were annotated into distinct blood cell types. The UMAP on the left shows that the cells are coming from different samples: untreated PBMC cells and cells treated with interferon beta (IFN-β). For this exercise, we are only examinig the cells that are IFN-β stimulation (labelled as stim the above UMAP).
The scRNA data is available from the Jupyter notebook but are also here in case it is needed: scRNA_25PBMC.h5ad
Examining the results
In this case study, we filtered the results to include only interactions where the source are the CD8 T cells sending communication signals to CD4 T and NK cells. We retained significant results with p-value less than 0.05. The choice to include just CD4 and NK cells only was an arbitrary threshold for this lab that was based on the observation of robust ligand signals for the CD8 T cells. In real life, we suggest that you look at all the possible significant interactions in each pair of cells and also consider the biological question under investigation.
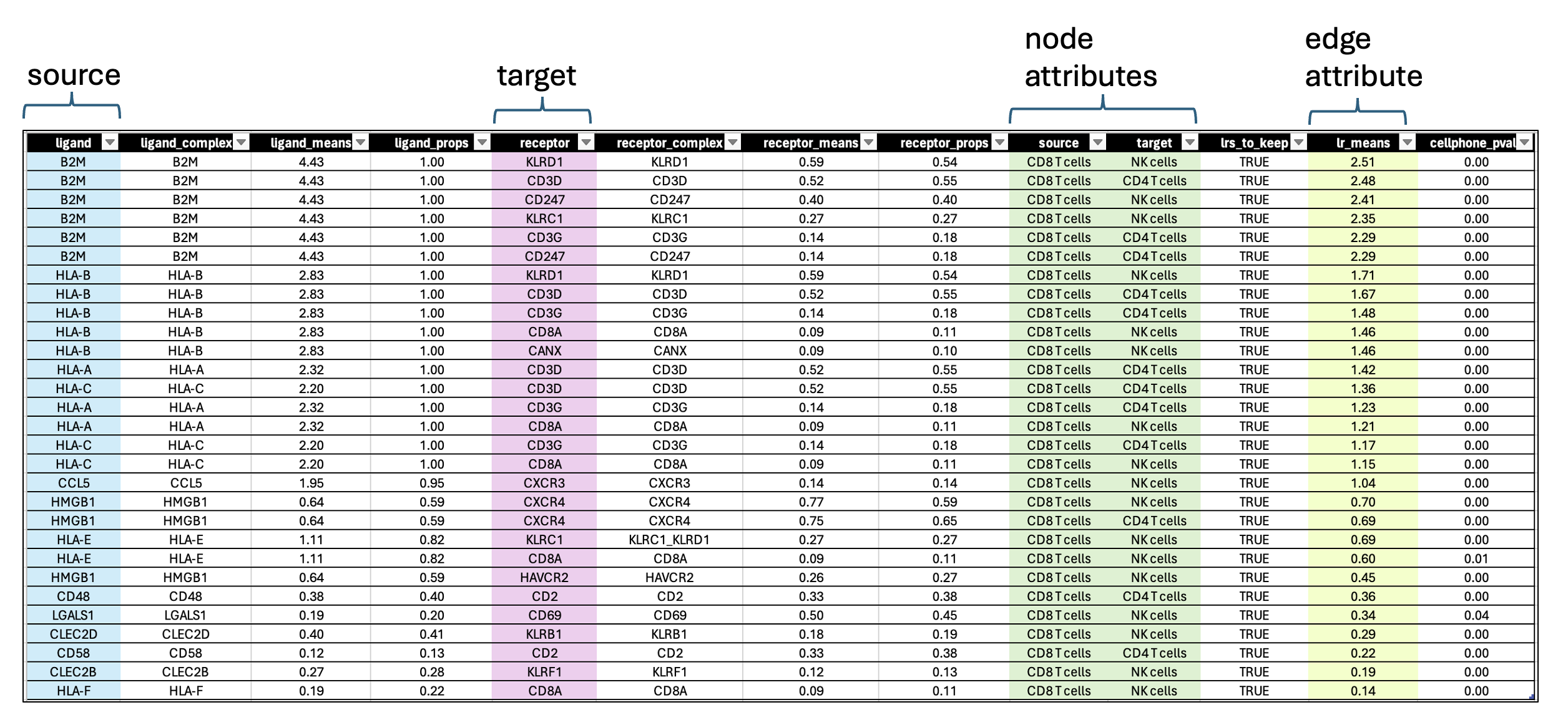
- each row contains a ligand-receptor pair with a different combination of source and target for each row.
- lr_means : (ligand-receptor means) is the average of ligand and receptor expression means.
- pvalue : indicates if this mean is far away from the mean of the null distribution.
- lrs_to_keep : indicates rows (ligand-receptor pairs) to keep based on the pvalue
- props : represents the proportion of cells that express the entity
Visualization using Cytoscape
A network is aimed to ease the visualization of relationships between entities. We will construct a directed network using the ligands from the CD8 T cells as source nodes and the detected receptors from CD4 T cells and NK cells as target nodes. The ligand and receptor entities will be represented as nodes on the network and we will color the nodes based on the cell types. The edge width will be proportional to the lr_means which represents the average of ligand and receptor mean expression and which is our measure of interaction strength.
To create this network, we don’t need any particular Cytoscape app. We will upload the CellPhoneDB result table as a custom network.
STEPS TO FOLLOW:
The filtered result from the Liana method can be found here: cellphoneDB_source_CD8_target_CD4_NK_p_0_05.csv Please download the file as you need it to create the network.
- Open Cytoscape.
- Go to the menu bar –> File –> Import –> Network from File …
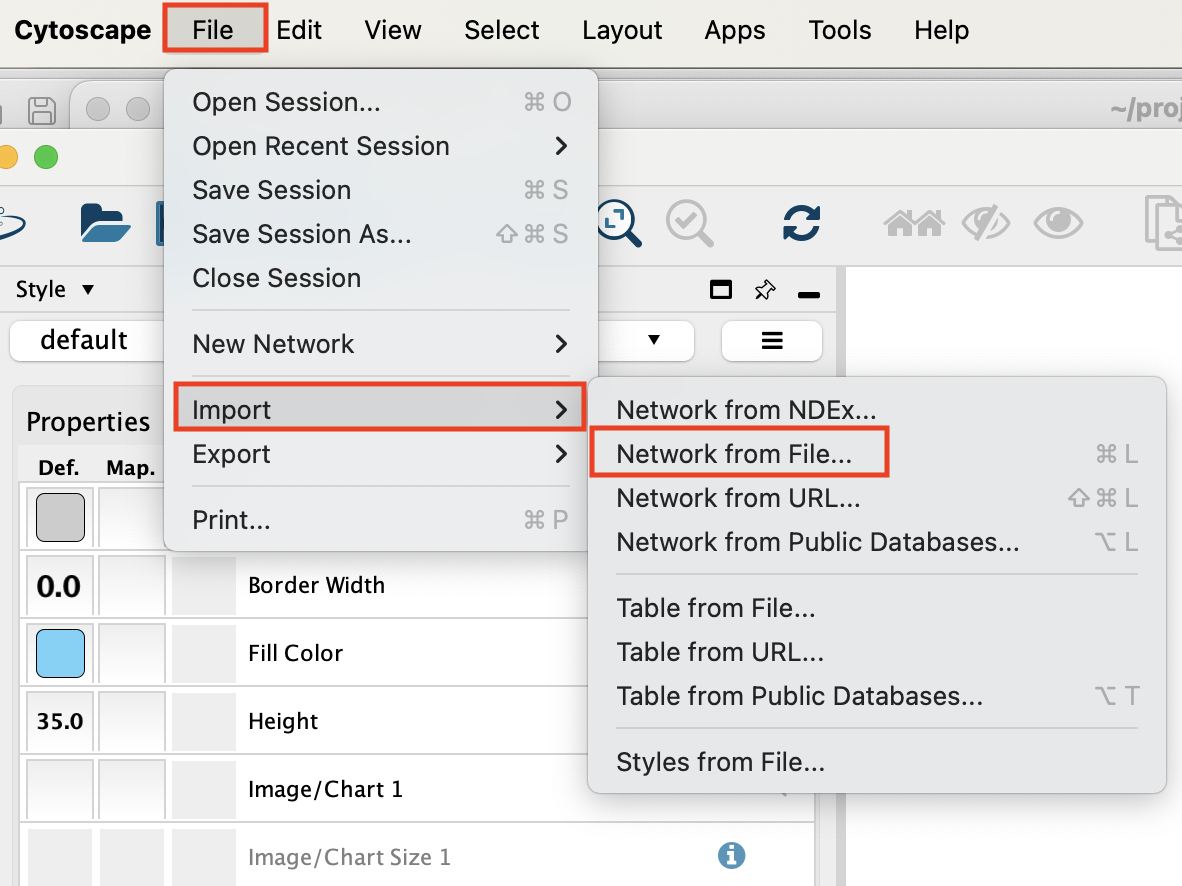
Select the file ‘cellphoneDB_source_CD8_target_CD4_NK_p_0_05.csv’ and click on ‘open’.
An ‘Import from Network table’ opens.
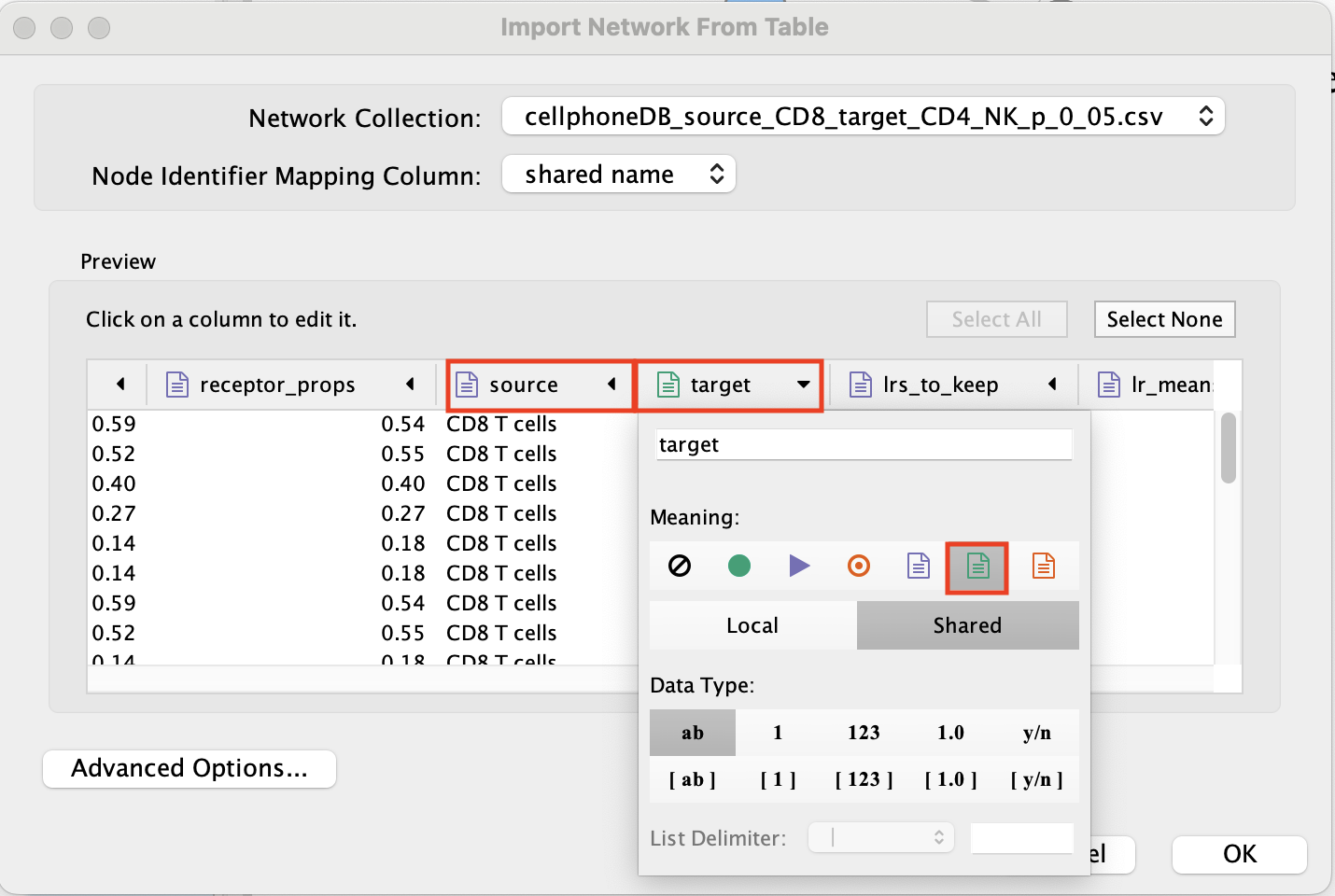
Set ‘ligand’ as source node.
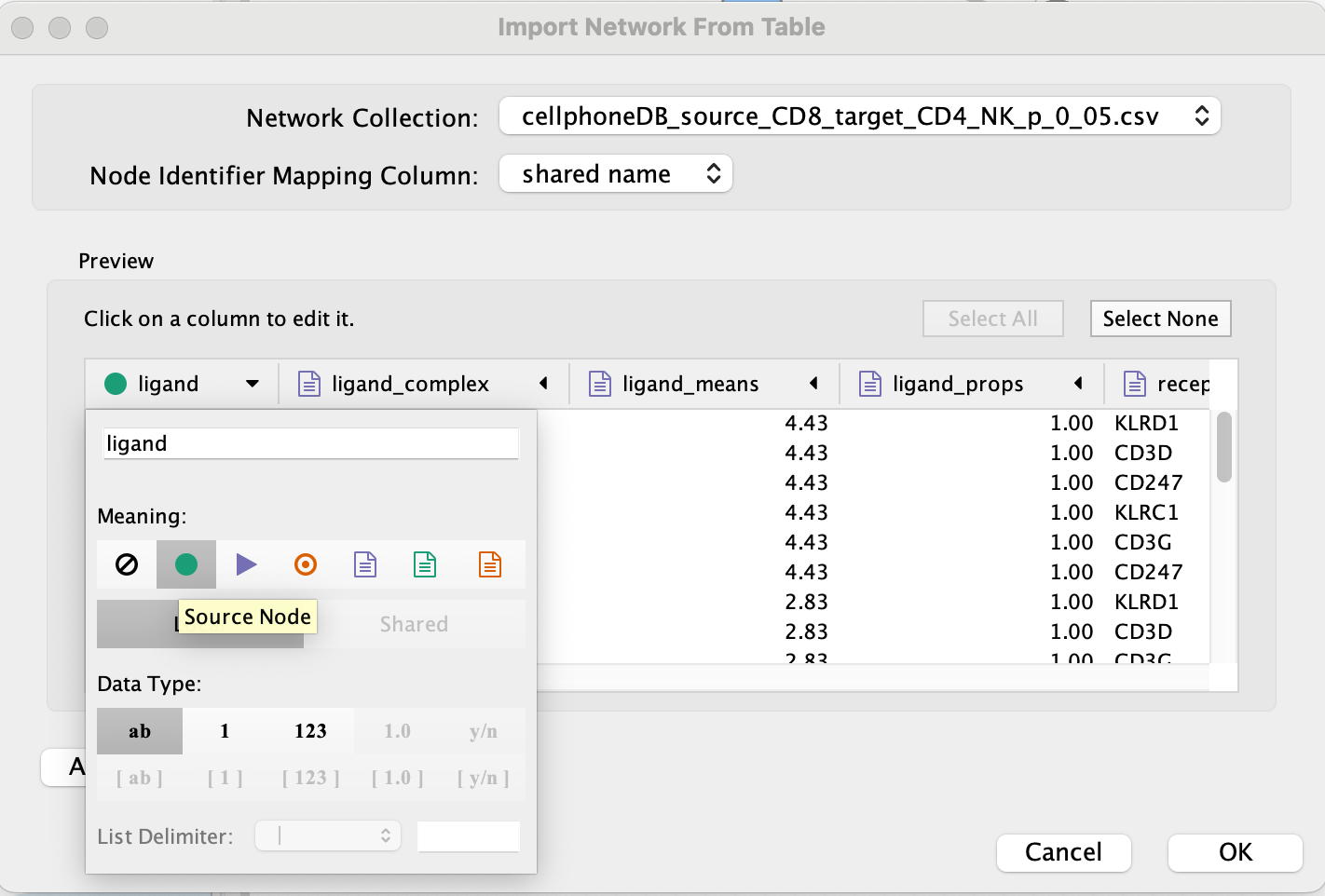
- Set ‘receptor’ as target node.
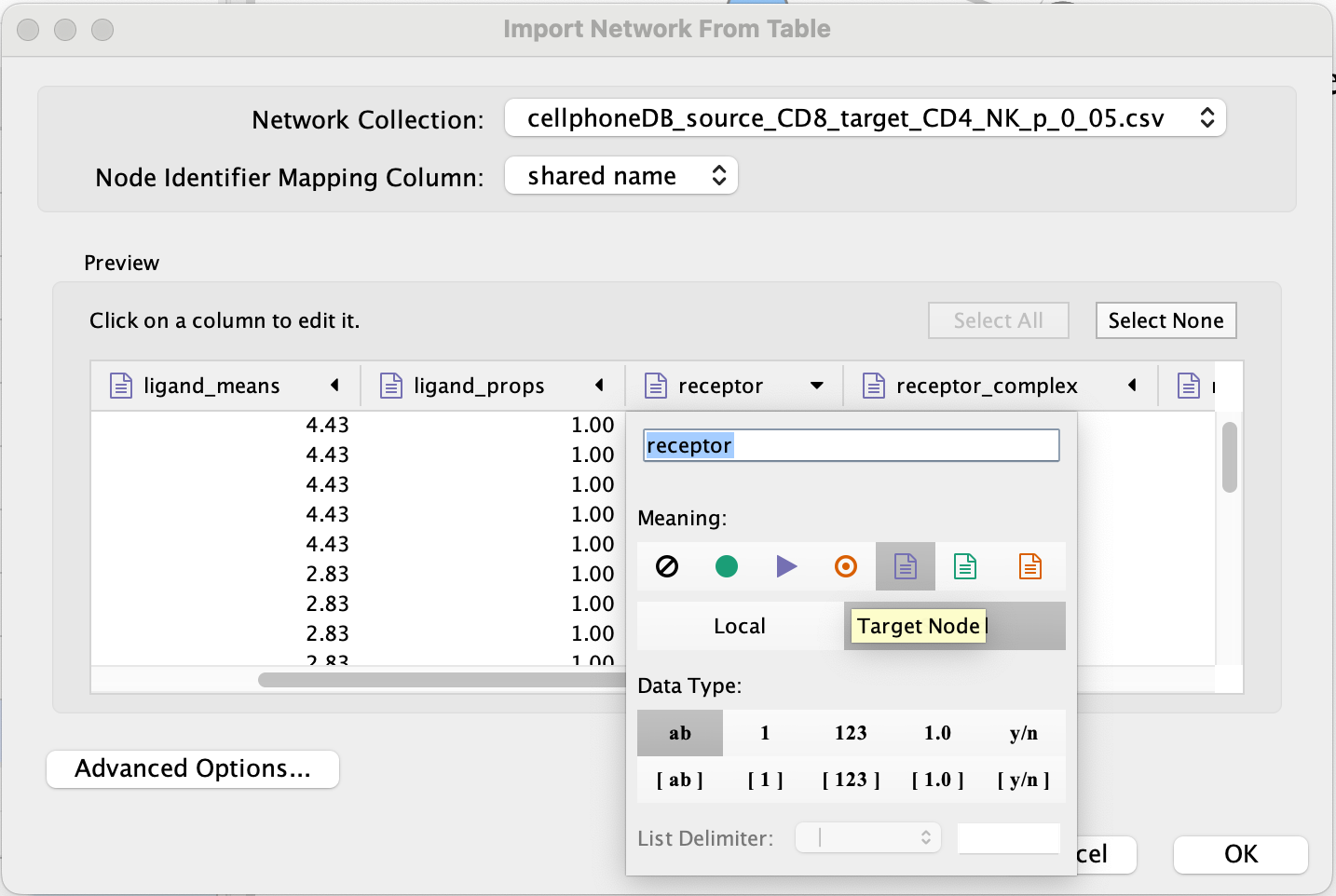
- Set source and target as ‘Source Node Attribute’.
Click on ‘OK’.
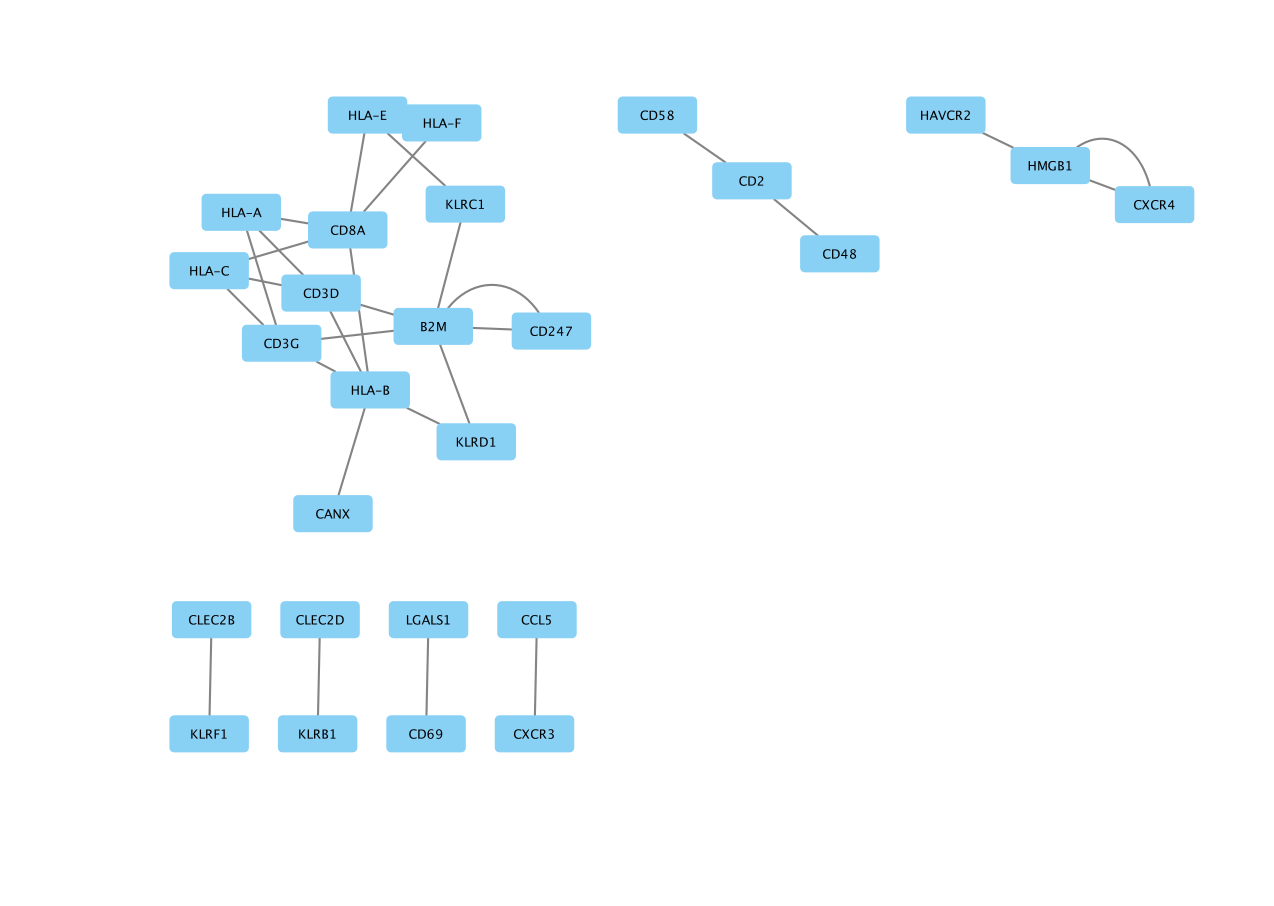
The network is created with the default style.
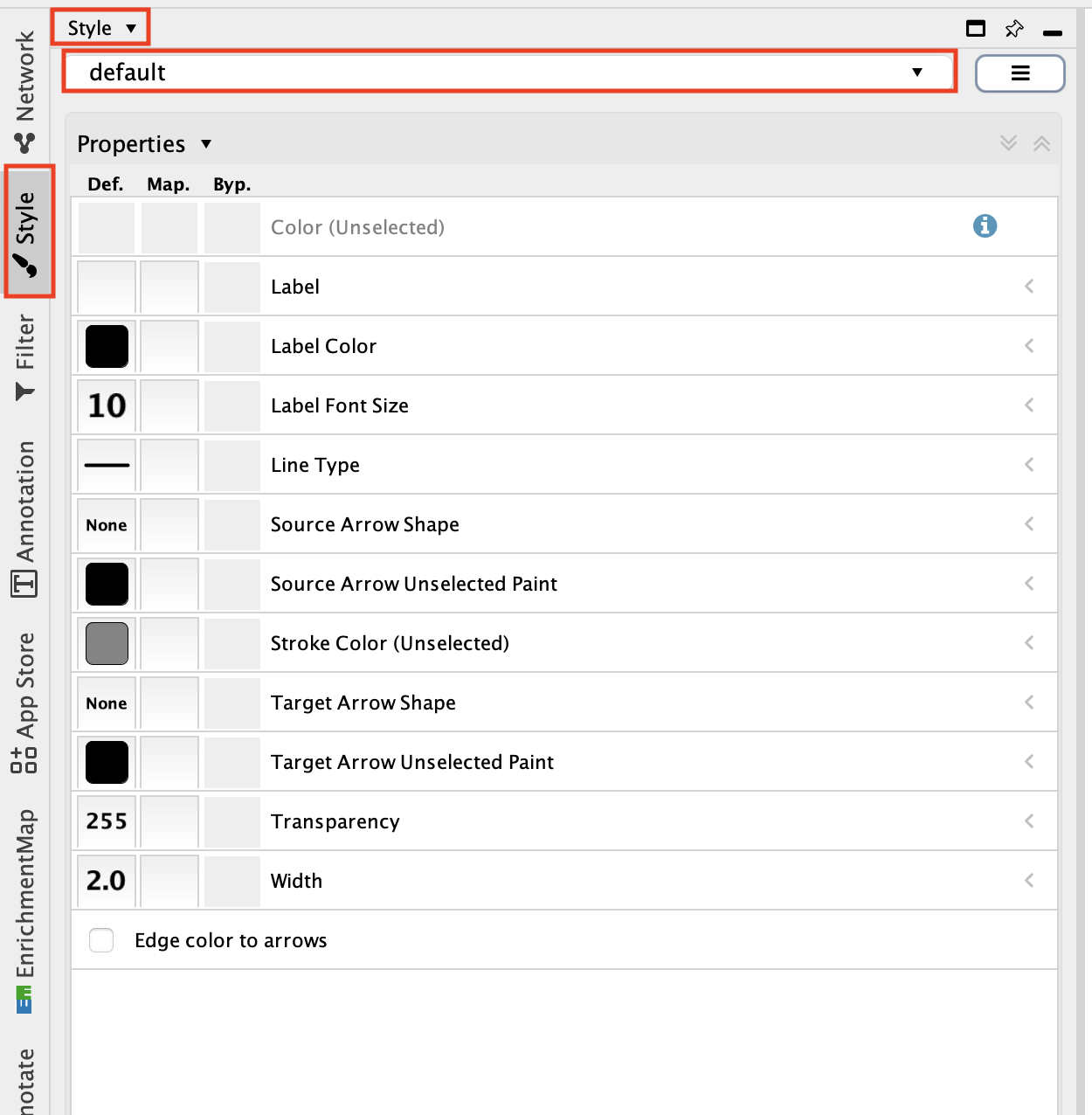
- Go to the ‘Style’ tab and change ‘Style’ from ‘Default’ to ‘Directed’.
Adjust the node style.
Go to the ‘Style’ tab and make sure that the ‘Node’ tab is selected.
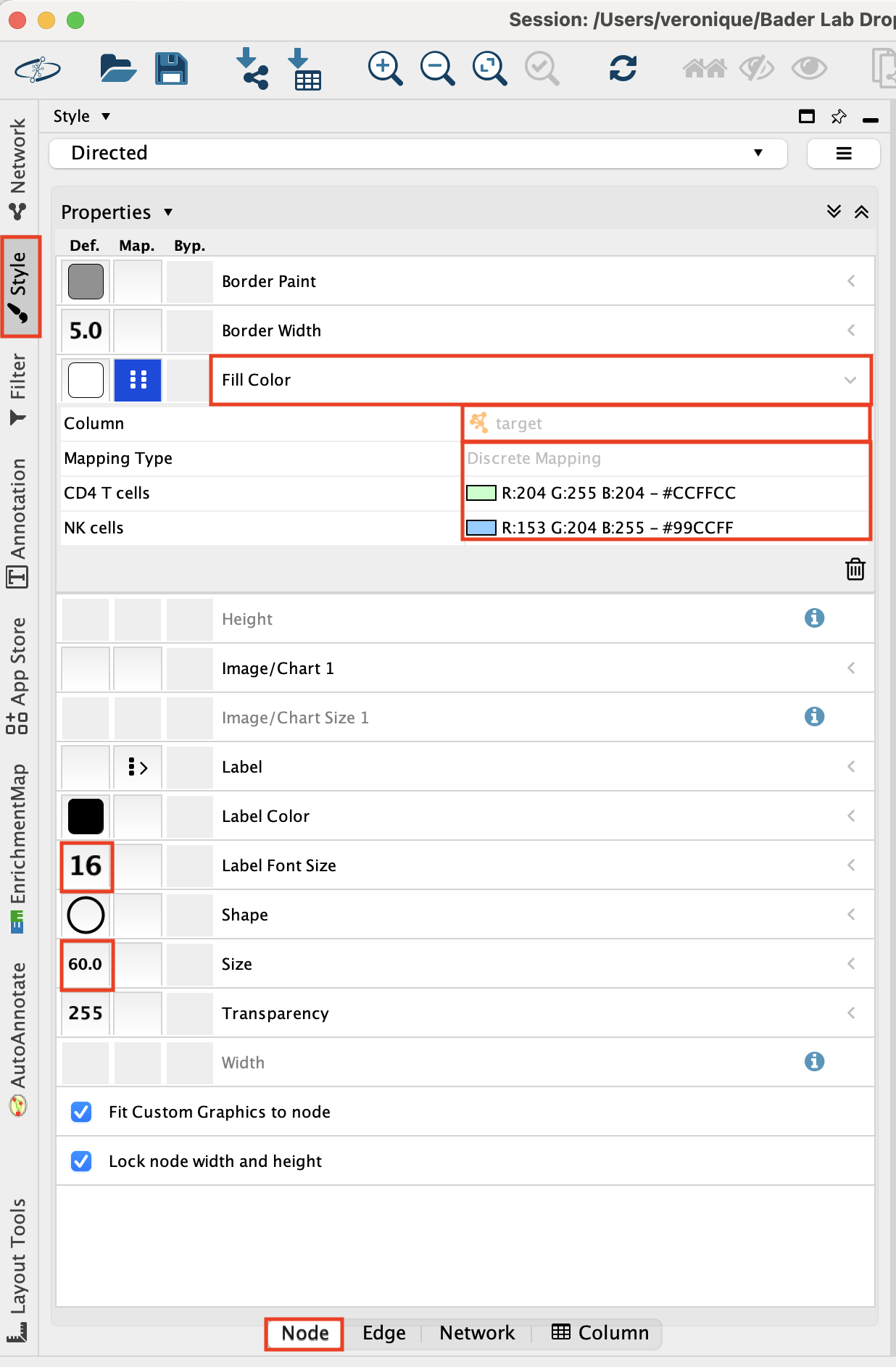
Adjust the ‘Fill Color’:
- Click on “Fill Color”.
- Click on the down arrow.
- Set ‘Column’ to ‘target’.
- Set ‘Mapping Type’ to “Discrete Mapping’ and click on the blanck space and on the”…” to set a color.
Set ‘Label Font Size’ to ‘16’.
Set ‘Size’ to ‘60’.
- Adjust the edge style.
- Go to the ‘Style’ tab and make sure that the ‘Edge’ tab is selected.
- Set “Label” to “lr_means”.
- Set “Width” to “lr_means”.
- Set “Width” - “Mapping type” to ‘Continuous Mapping’
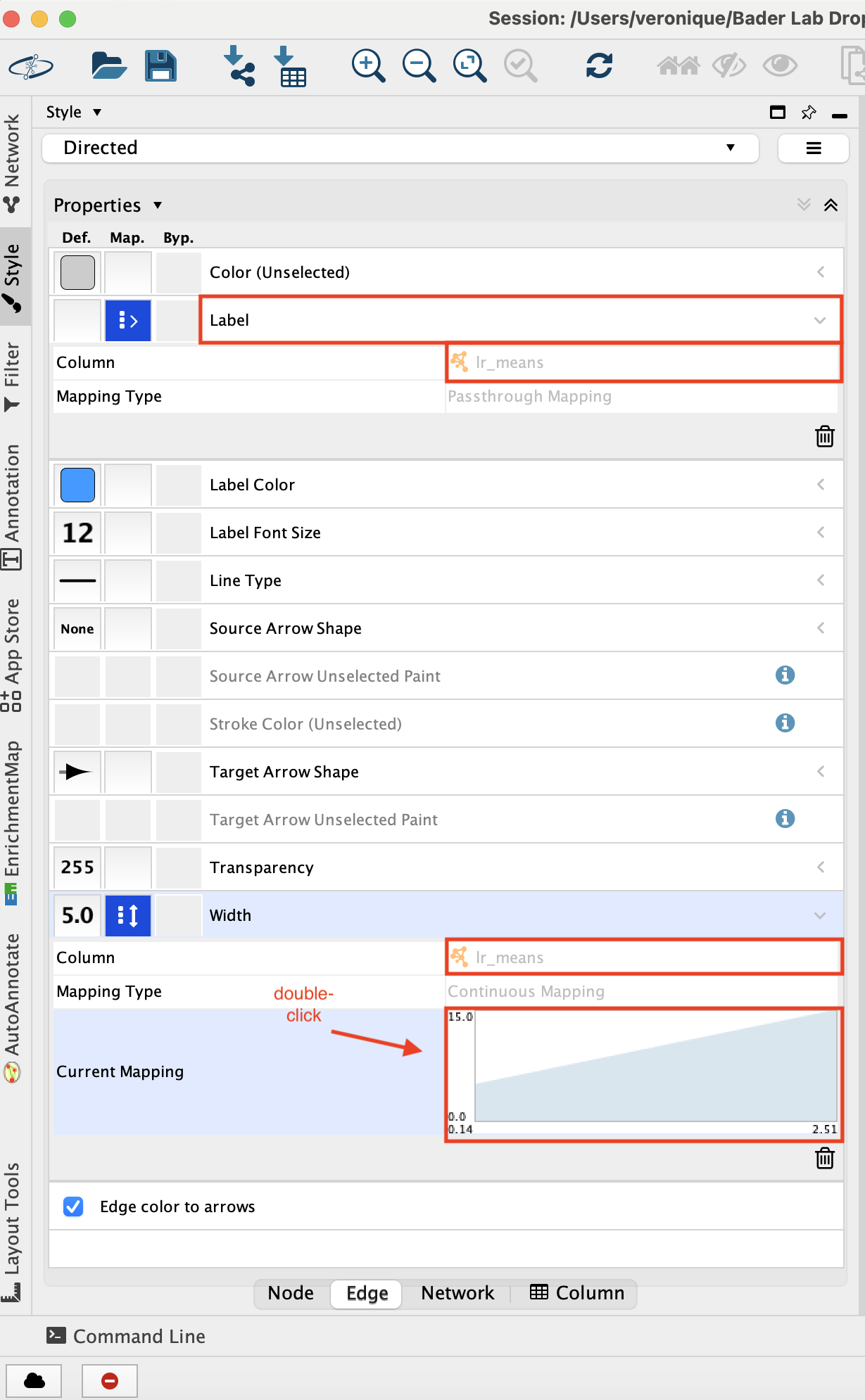
- Double click on the chart that shows up to adjust the parameters.
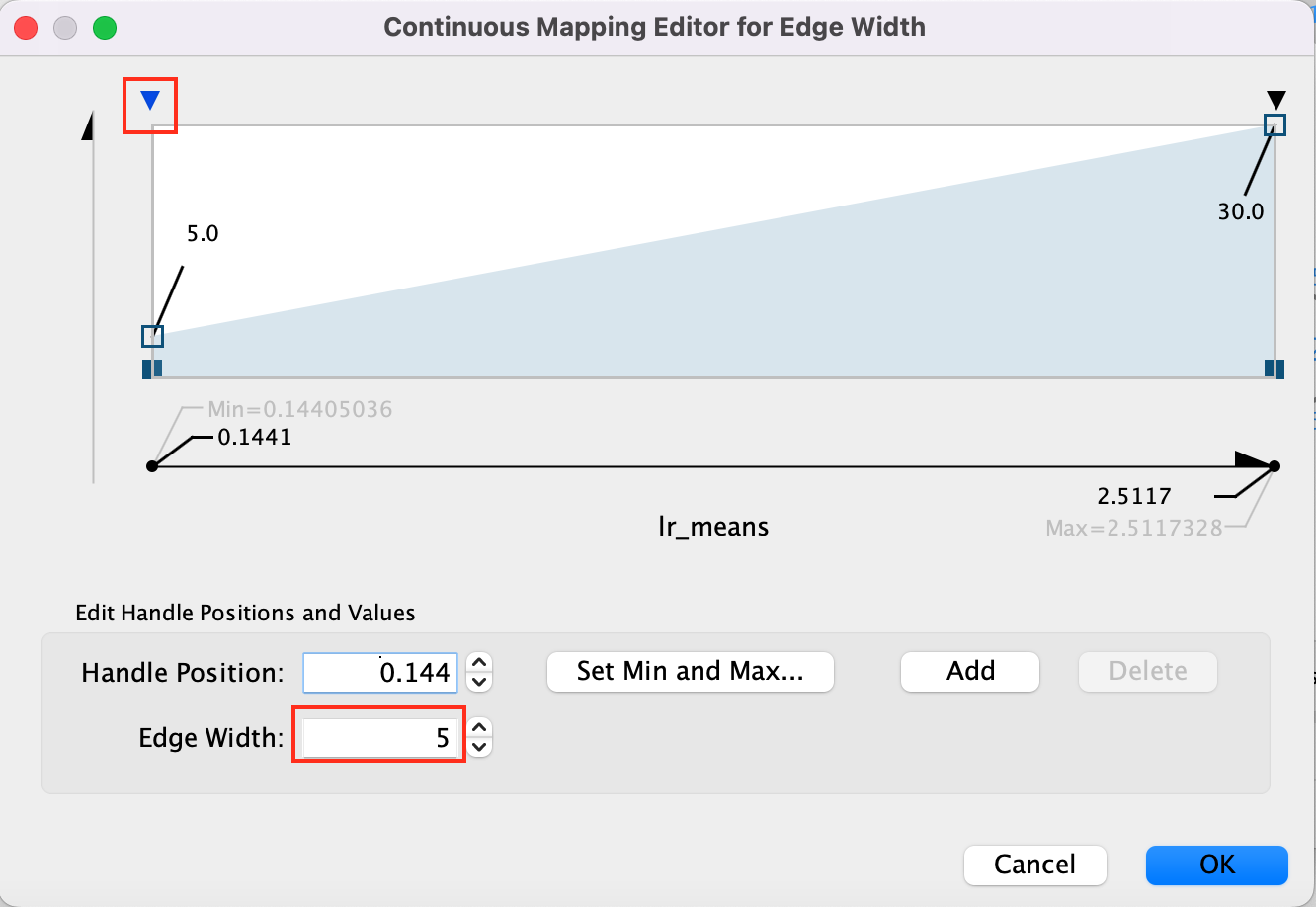
- Adjust minimum width to 5 adn maximum width to 15 -
- Click on the top arrow and then set the edge width to 5. Press enter to register the change.
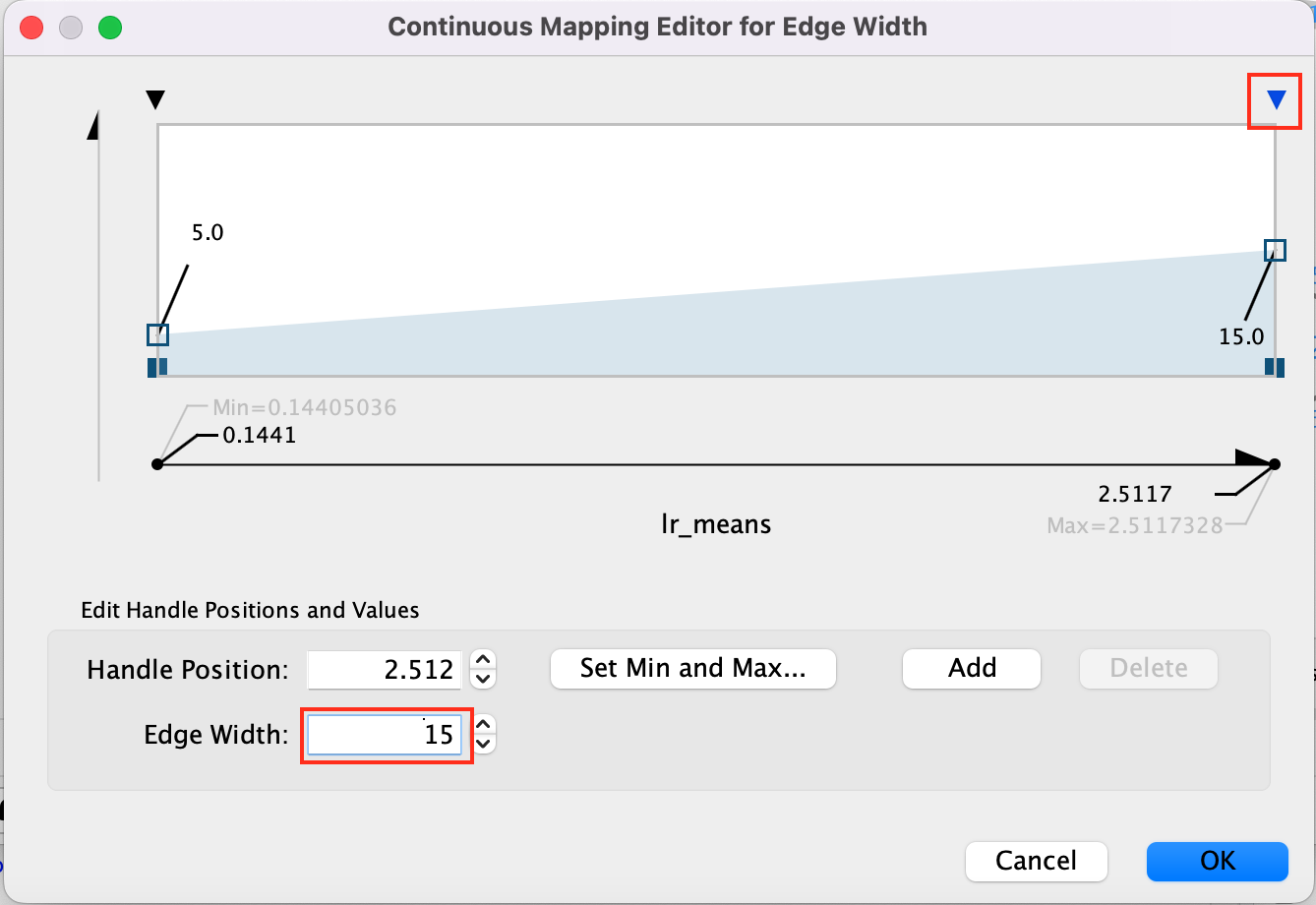
- Click on the top right arrow and then set the edge width to 15. Press enter to register the change.
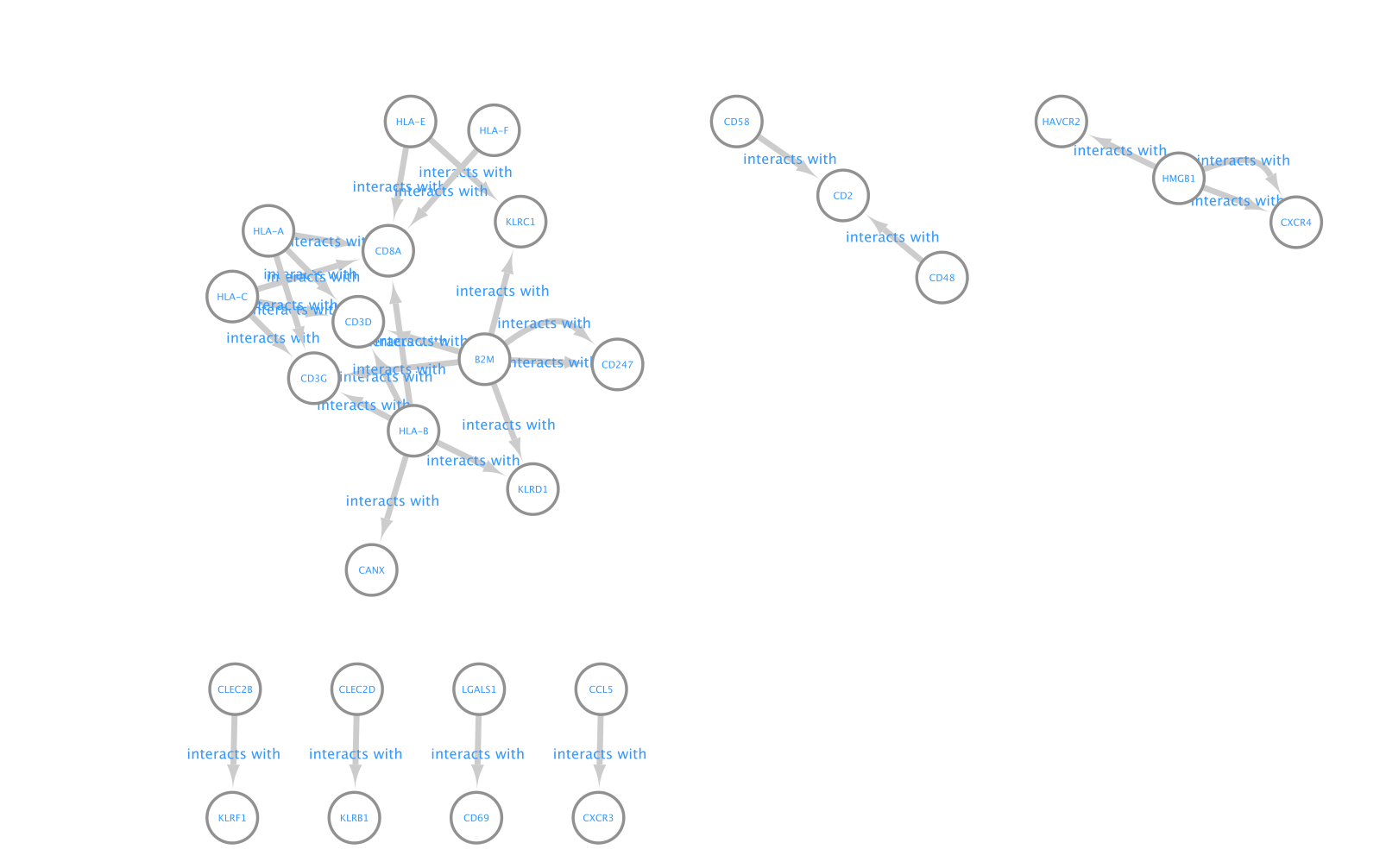
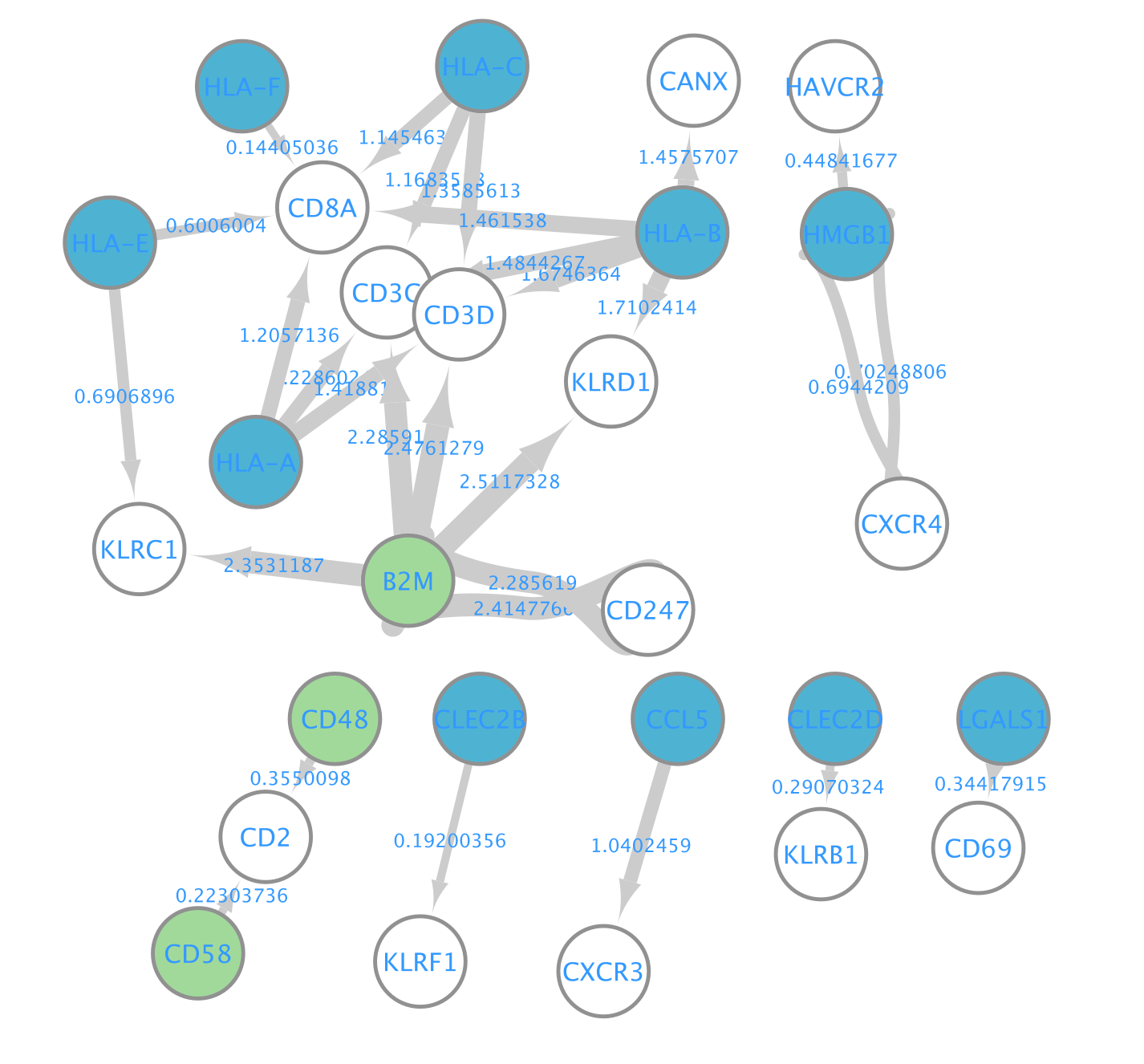
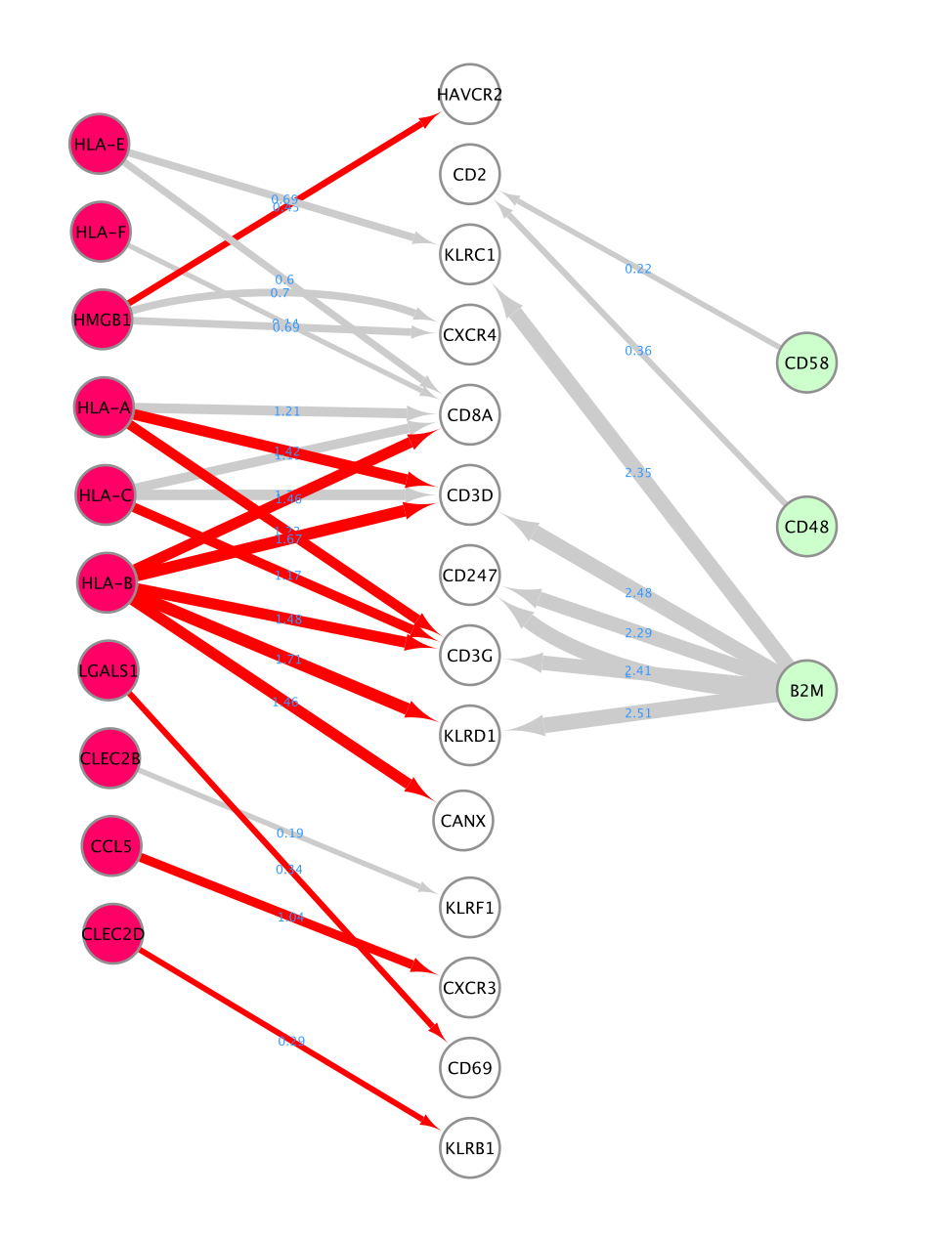
- Here is the resulting network:
- Align the nodes so that the ligands from the CD8 cells are in the middle and the receptors from NK and CD4 cells on the left and right side.
- You can do it manually. Alternatively, you can use the layout tools.
- Select the nodes of interest, go to the ‘layout tools’ and click on a align or distribute option.
- Add annotation:
- Right click on a blank space and add an annotation.
- Right click on a blank space and add an annotation.
- Here is the final result:
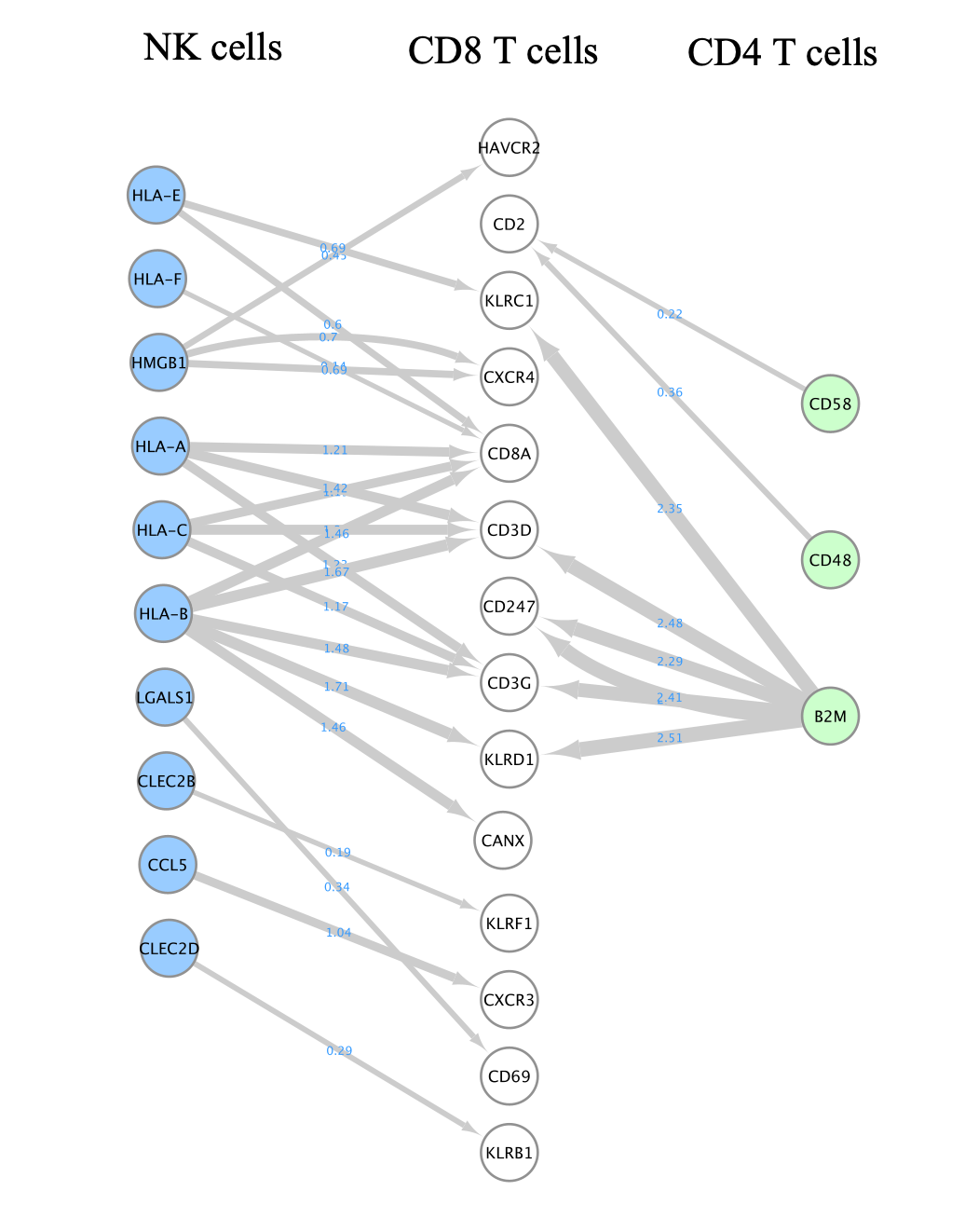
- Do not forget to save your session. You can also export the network as an image.
Dataset and references
Reference paper: Multiplexed droplet single-cell RNA-sequencing using natural genetic variation. Kang et al. Nat Biotechnol. 2018 Jan;36(1):89-94., PMID: 29227470
References used to build the Jupyter notebook and run CellPhoneDB:
Dataset preprocessing and running CellPhoneDB
Do not run during practical lab. This is for your information only.
CellPhoneDB is a python package. Running CellPhoneDB is out of score for this lab but the annotated code is included in totality in this Jupyter notebook and is available for download using these links :
CellPhoneDB_jupyter_notebook.pdf
CellPhoneDB_jupyter_notebook.ipynb
Some installation instructions are placed at the top of the document.
- Running CellPhoneDB: The provided Jupyter notebook contains 2 methods to run CellPhoneDB. The first method is to run CellPhoneDB using the Liana package. This method is simple and allows for the comparison with other cell-cell communication tools also included in the Liana package. (See part 1 of the notebook). The second approach is to run it directly from the CellPhoneDB package. It offers the advantage to choose the version of the ligand-receptor database and to run it from 3 offered methods: basic, statistical and DEG-based. This is part 2 of the notebook.
Please consult the CellPhoneDB webpage and gihub links provided at the top of the document as they contain detailed information and tutorials.