Module 3 Lab: GSEA Visualization
This work is licensed under a Creative Commons Attribution-ShareAlike 3.0 Unported License. This means that you are able to copy, share and modify the work, as long as the result is distributed under the same license.
By Veronique Voisin, Ruth Isserlin, Gary Bader
Goal of the exercise:
Exercise 1 - Create an enrichment map and navigate through the network
During this exercise, you will learn how to create an EnrichmentMap from gene-set enrichment results. The enrichment tool chosen for this exercise is GSEA but an enrichment map can be created from output from GSEA, g:Profiler, GREAT, BinGo, Enrichr or alternately from any gene-set tool using the generic enrichment results format.
Exercise 2 - Post analysis (add drug target gene-sets to the network)
As second part of the exercise, you will learn how to expand the network by adding an extra layer of information.
Exercise 3 - Autoannotate
A last optional exercise guides you through the creation of automatically generated cluster labels to the network.
Data
The data used in this exercise is gene expression data obtained from high throughput RNA sequencing. The data correspond to Pancreatic Ductal Adenocarcinoma samples (TCGA-PAAD). We use precomputed results of the GSEA analysis Module 2 lab - gsea to create an enrichment map with the aim to transform the tabular format to a network so we can better visualize the relationships between the significant gene-sets:
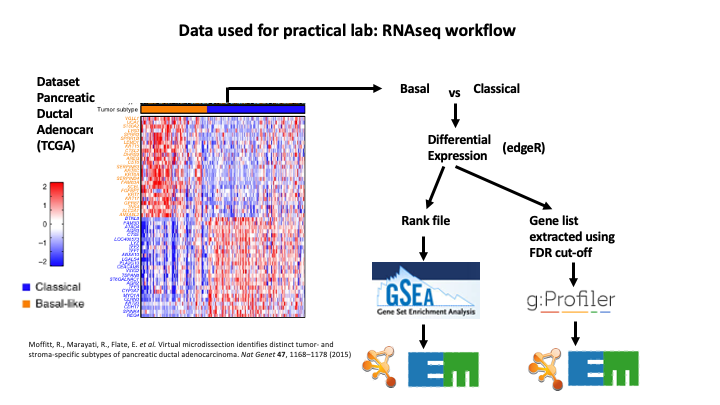
GSEA outpus an entire directory of files and results. For the purpose of this analysis we only need two tables found in the output directory. The output result tables are:
One table (pos) contains all pathways with an enrichment score (significant or not) related to enrichment of the basal category (positive score). (By default called - gsea_report_for_na_pos_#############.tsv)
One table (neg) contains all pathways with an enrichment score (significant or not) related to enrichment of the classical category (negative score). (By default called - gsea_report_for_na_neg_#############.tsv)
These 2 tables are uploaded using the EnrichmentMap App which will create a network of basal and classical pathways that have a significant score (FDR <= 0.05) for clearer visualization of the results.
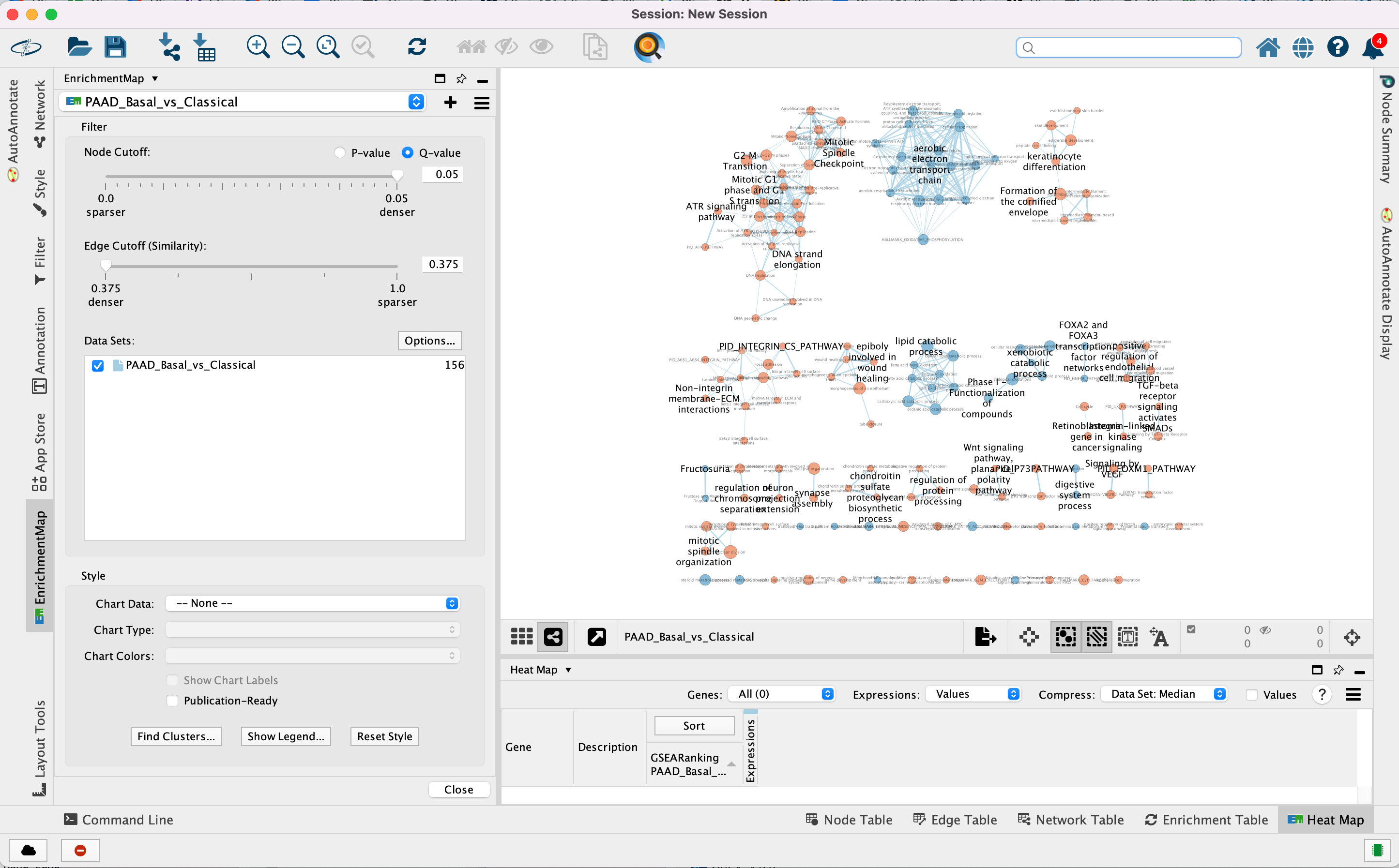
EnrichmentMap
A red circle (node) is a pathway specific of the mesenchymal type. (or pathway with mostly positively ranked genes)
A blue circle (node) is a pathway specific of the immunoreactive type. (or pathway with mostly negatively ranked genes)
An edge represents genes in common between 2 pathways (nodes).
A cluster of nodes represent overlapping and related pathways and may represent a common biological process or theme.
Clicking on a node will display the genes included in each pathway.
Exercise 1 - GSEA output and EnrichmentMap
To start the lab practical section, first download the files.
Right click on link below and select “Save Link As…”.
Place it in the corresponding module directory of your CBW work directory.
7 Files are needed to create the enrichment map for this exercise (please download these files on your computer or alternately use the GSEA directory created in module 2 lab - gsea for files 1,2,3) :
GMT (file containing all pathways and corresponding genes) - Human_GOBP_AllPathways_noPFOCR_no_GO_iea_June_01_2024_symbol.gmt
Enrichments 1 (GSEA results for the “pos” basal subtype) - gsea_report_for_na_pos_1717773429384.tsv
Enrichments 2 (GSEA results for the “neg” Classical subtype) - gsea_report_for_na_neg_1717773429384.tsv
Expression (file containing the RNAseq data for all samples and all genes) - TCGA-PAAD_GDC_BasalvsClassical_normalized_rnaseq.txt
Rank file (file that has been used as input to GSEA) - TCGA-PAAD_GDC_Subtype_Moffitt_BasalvsClassical_ranks.rnk
Classes (define which samples are basal and which samples are classical) - TCGA-PAAD_Subtype_Moffitt_BasalvsClassical_RNAseq_classes.cls
Drug target database (preselection of 7 drugs and their target genes in the post analysis exercise, http://www.drugbank.ca/) - Human_DrugBank_all_symbol_June_01_2024_selected.gmt
Follow the steps described below at your own pace:
Step 1
Launch Cytoscape and open EnrichmentMap App
1a. Double click on the Cytoscape icon
1b. Open EnrichmentMap App
In the top menu bar:
- Click on Apps -> EnrichmentMap
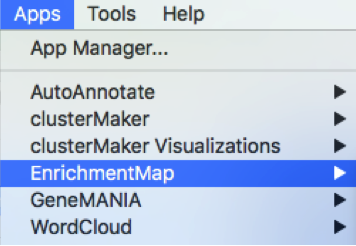
A ’Create EnrichmentMap window is now opened.
Step 2
Create an enrichment map
2a. In the ‘Create EnrichmentMap’ window, add a dataset of the GSEA type by clicking on the ‘+ADD…’ –> ‘+ add data set manually’.
2b. Specify the following parameters and upload the specified files:
Name: leave default or a name of your choice like “GSEAmapPAAD_Basal_vs_Classical”
Analysis Type: GSEA
Enrichments Pos: gsea_report_for_na_pos_1717773429384.tsv
Enrichments Neg: gsea_report_for_na_neg_1717773429384.tsv
GMT : Human_GOBP_AllPathways_noPFOCR_no_GO_iea_June_01_2024_symbol.gmt
Ranks: TCGA-PAAD_GDC_Subtype_Moffitt_BasalvsClassical_ranks.rnk
Expressions : TCGA-PAAD_GDC_BasalvsClassical_normalized_rnaseq.txt
This field is optional but recommended.
Classes: TCGA-PAAD_Subtype_Moffitt_BasalvsClassical_RNAseq_classes.cls
This field is optional.
Phenotypes: In the text boxes place Basal as the Positive phenotype Classical as the Negative phenotype. Basal will be associated with red nodes because it corresponds to the positive phenotype and Classical will be associated with the blue nodes because it corresponds to the negative phenotype.
Set FDR q-value cutoff to 0.05 (= only gene-sets significantly enriched at a value of 0.05 or less will be displayed on the map).
If the cutoff is set to a very small number, for exaxmple 0.0001, it will be displayed as 1E-04 in the scientific notation.
2c. Click on Build
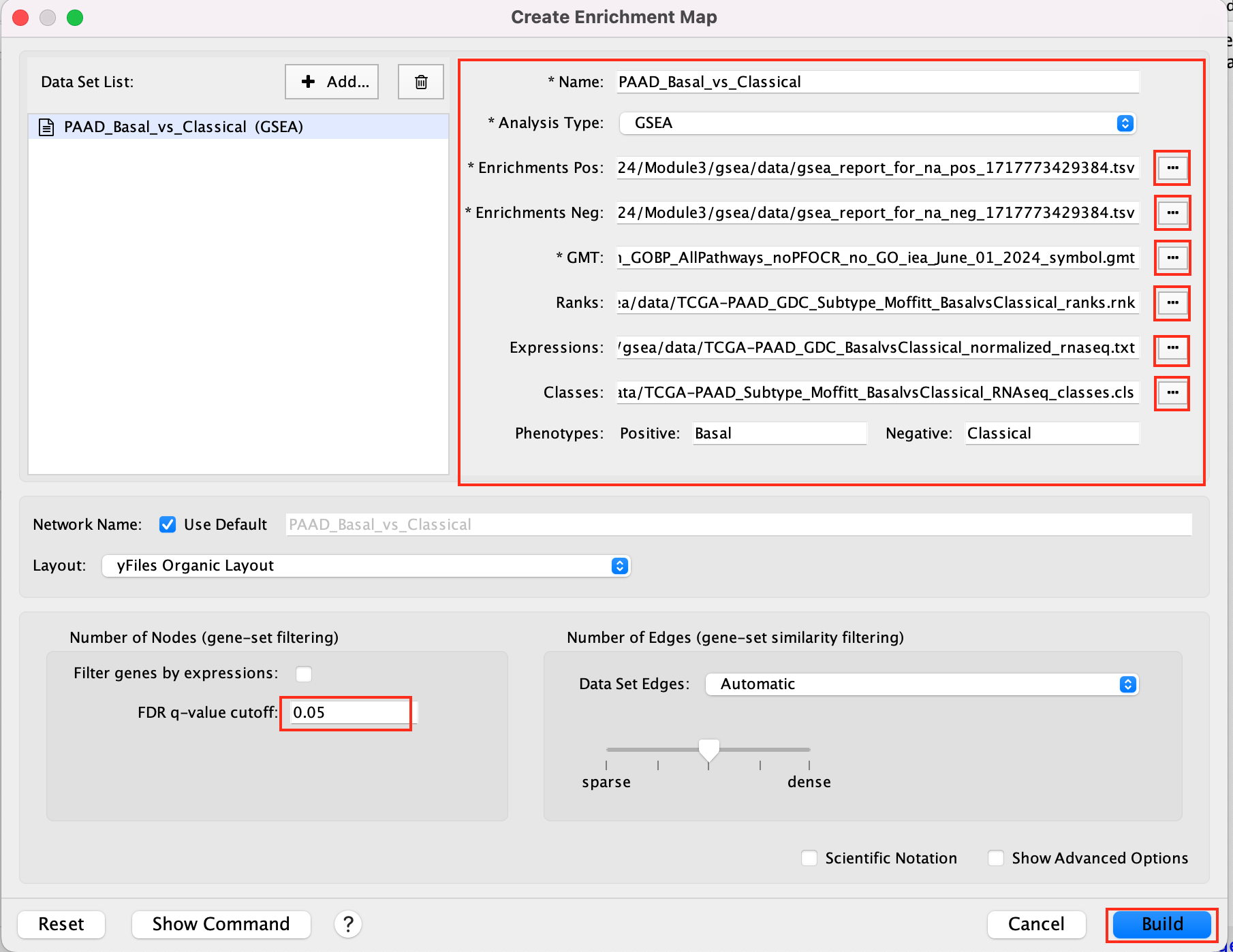
We populated the fields manually. If you work with your own data, a way to populate automatically the fields is to drag and drop your GSEA folder in the ‘Data Set’ window. You are encouraged to give it a try once you finished the lab with your own GSEA results.
Unformatted results:
layout will be different for each user (there is a random seed in the layout algorithm) but it does not change the results or interpretation (the connections are the same, only the display is different).
Step 3
Navigate the enrichment map to gain a better understanding of a EnrichmentMap network.
General layout of Cytoscape panel: In addition to the main window where the network is displayed, there are 2 panels: the Control Panel on the left side and the Table Panel at the bottom of the window.
Steps:
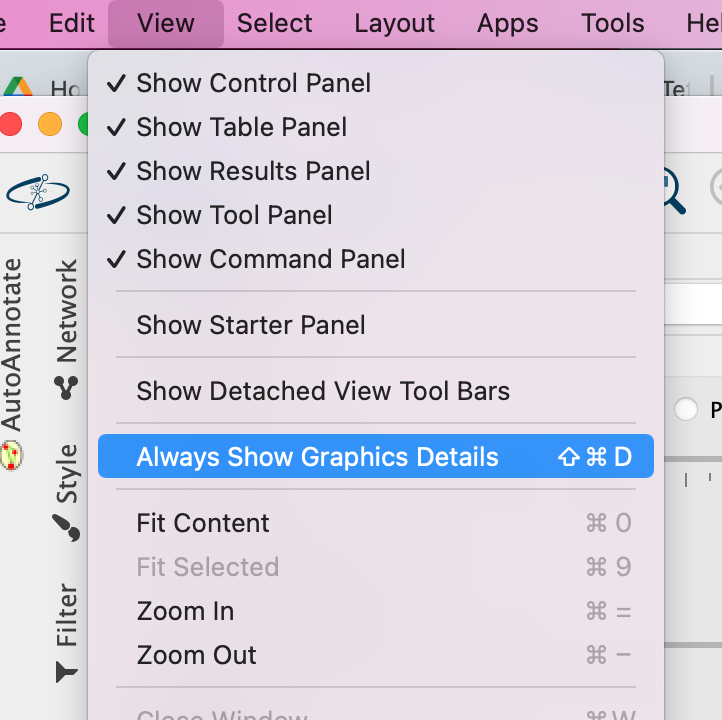
3a. In the Cytocape menu bar, select View and Always Show Graphic details. It will turn the squared nodes into circles and the gene-set labels will be visible.
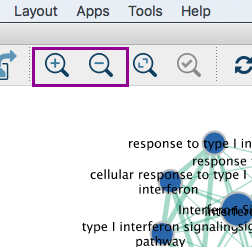
3b: Zoom in or out using + or - in toolbar or scroll button on mouse until you are able to read the labels comfortably.
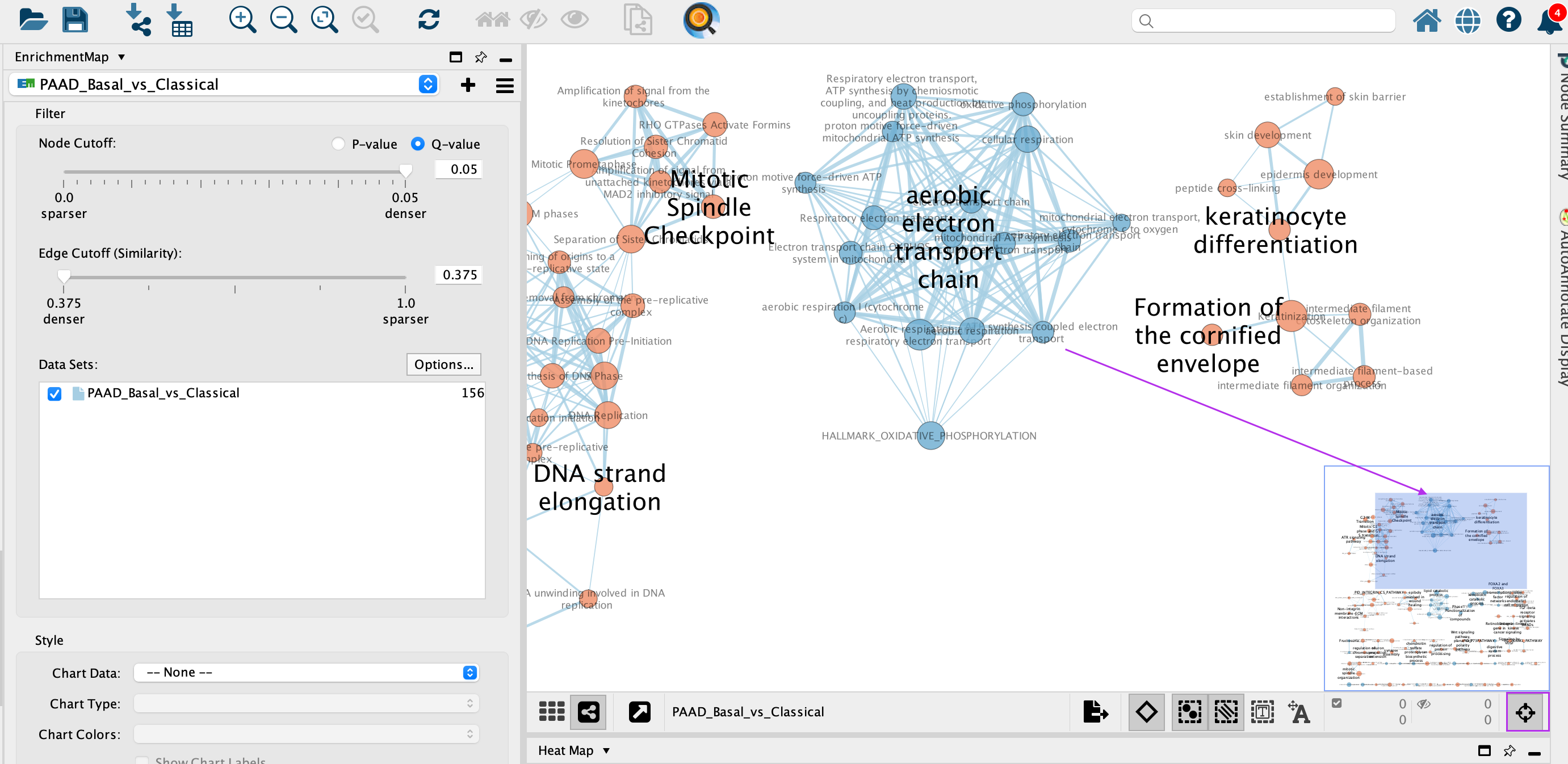
3c: Use the bird’s eye view (located at the bottom of the control panel) to navigate around the network by moving the blue rectangle using the mouse or trackpad.
3d: Click on an individual node of interest.
For this example, you could use TGF-BETA RECEPTOR SIGNALING ACTIVATES SMADS.
If you are unable to locate TGF-BETA RECEPTOR SIGNALING ACTIVATES SMADS, type “TGF-BETA RECEPTOR SIGNALING ACTIVATES SMADS” in the search box (quotes are important). Selected nodes appear yellow (or highlighted) in the network.
3e. In the Table Panel in the EM Heat map tab change:
Expressions: Row Norm
Compress: -None-
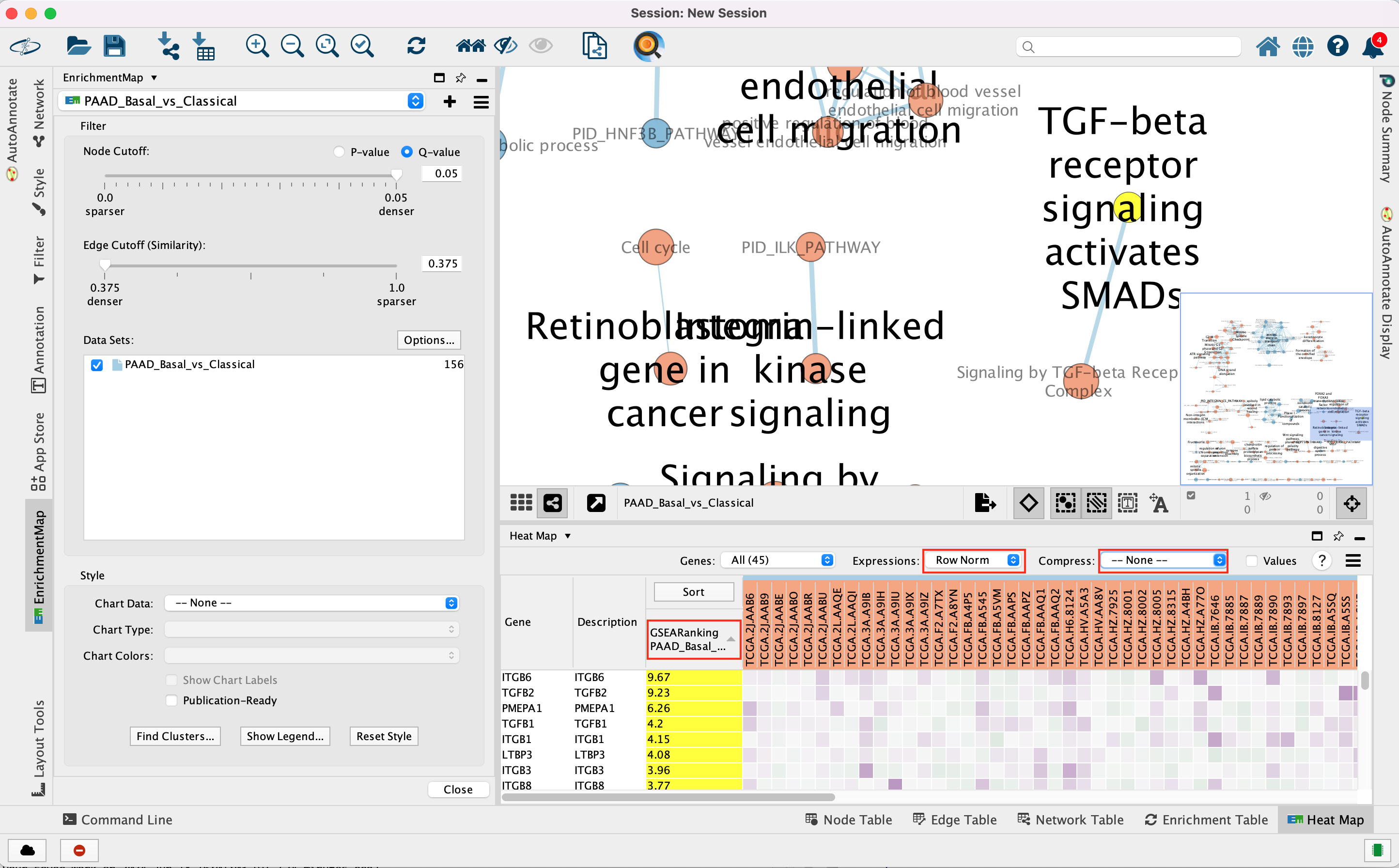
Genes in the heatmap that are highlighted yellow (rank column)
represent genes that are part of the leading edge for this gene set,
i.e. contributed the most to the enriched phenotype.
Leading edge
genes will only be highlighted if an individual node has been selected
and the Enrichment Map was created from GSEA results.
Troubleshooting: if you don’t see the sort column highlighted
in yellow, reselect the node of interest and click on the GSEARanking
Data Set 1 text in the EM Heatmap tab.
Step 4
Use Filters to automatically select nodes on the map: Move the blue nodes to the left side of the window and the red nodes to the right side of the window.
4a. Locate the Filter tab on the side bar of the Control Panel.
4b. Click on the + sign to view the menu and select Column Filter.
4c. From the Choose column … box, select Node: NES(PAAD_Basal_vs_Classical) and set filter values from -2.242 and 0 inclusive.
4d. The blue nodes are now automatically selected. Zoom out to be able to look at the entire network and drag all blue nodes to the left side of the screen.
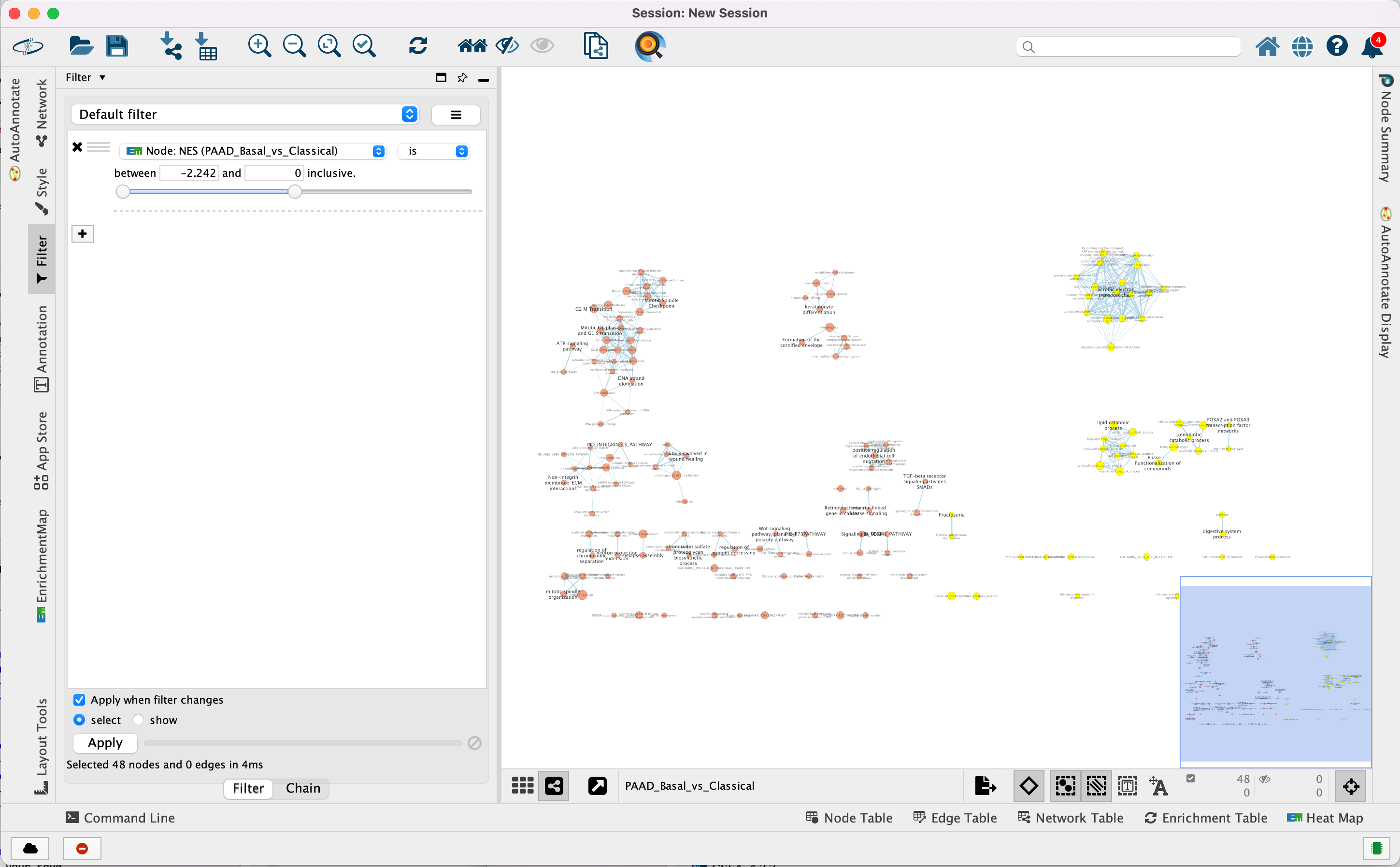
4e. Optional. Change is to is not to select the red nodes.
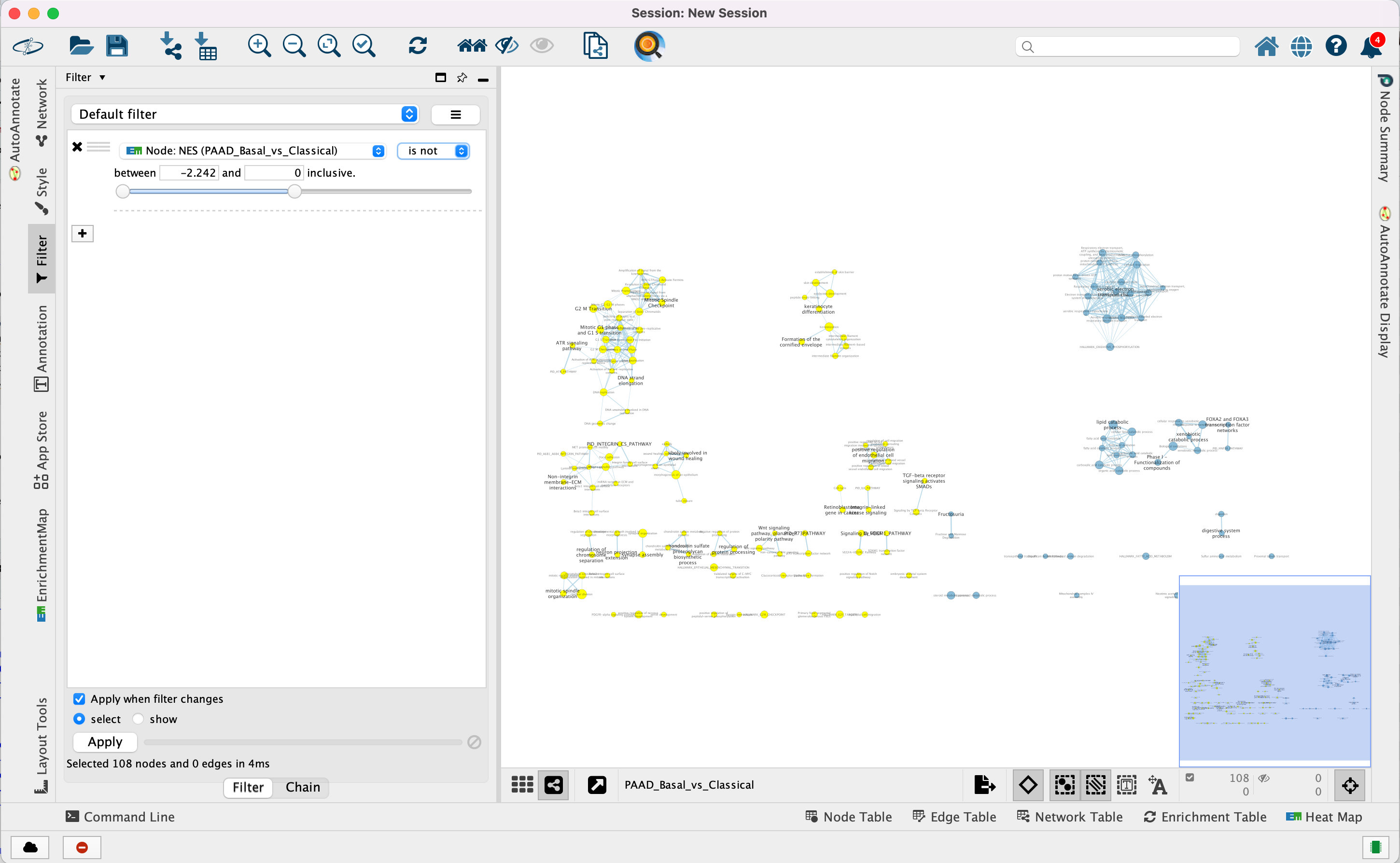
The red pathways (nodes) are specific to the Basal subtype. They were
listed in the pos table of the GSEA results. The enrichment
score (ES) values in this table are all positive values.
The blue pathways are specific to the Classical subtype and were
listed in the neg table of the GSEA results. The ES values in
this table are all negative values.
This is the information we used as the filtering criteria.
Exercise 2 - Post analysis (add drug target gene-sets to the network)
Step 5
Add drug target gene-sets to the network (Add Signature Gene-Sets…).
5a. In Control Panel, go to the EnrichmentMap tab and click on “Options…” located above the ‘Data Sets:’ box. Select “Add Signature Gene Sets…”. A window named “EnrichmentMap: Add Signature Gene Sets (Post-Analysis) is now opened.
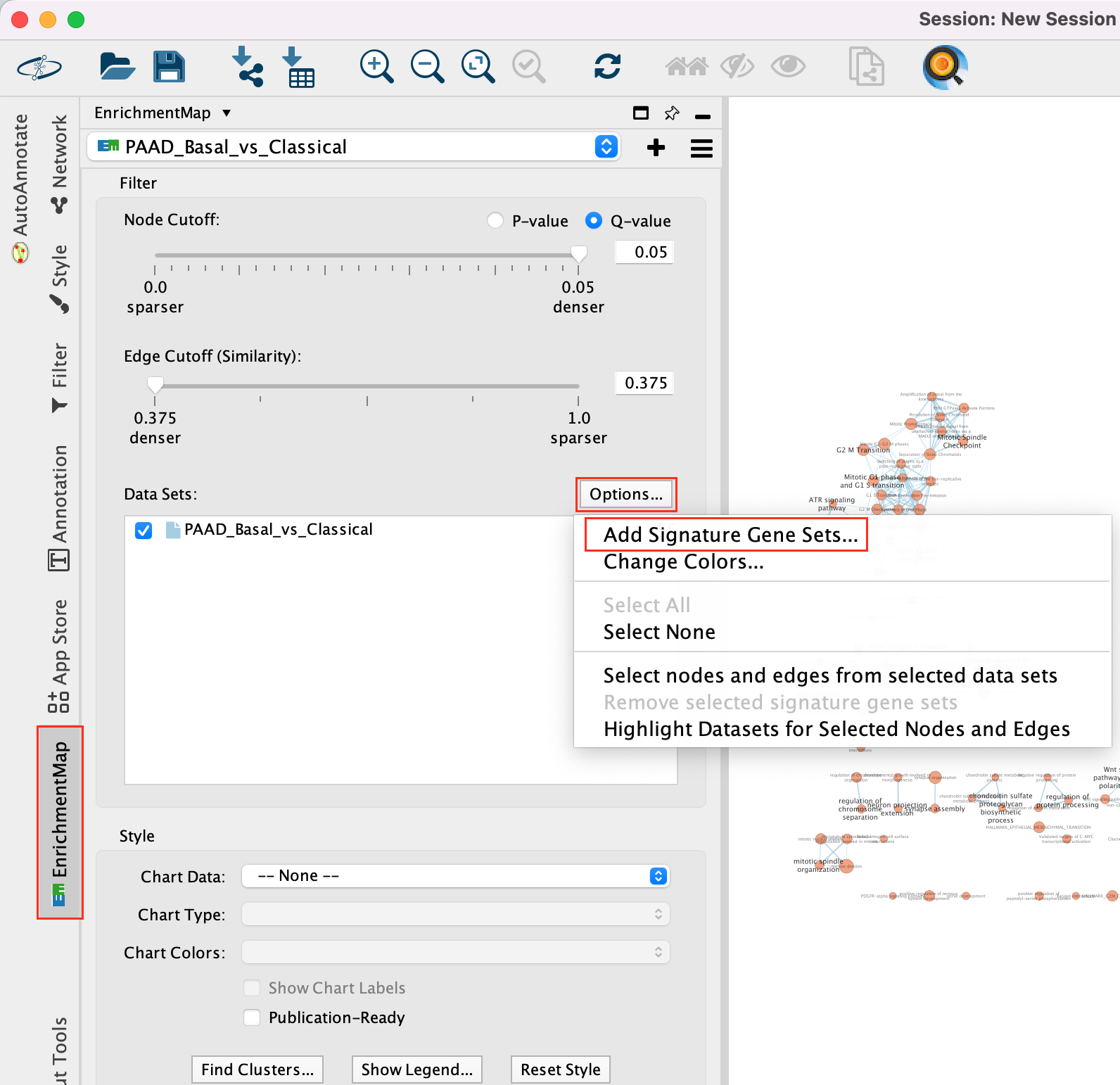
5b. Using the ‘Load from File…’ button, select the Human_DrugBank_approved_symbol_June_01_2024_selected.gmt file that you saved on your computer.
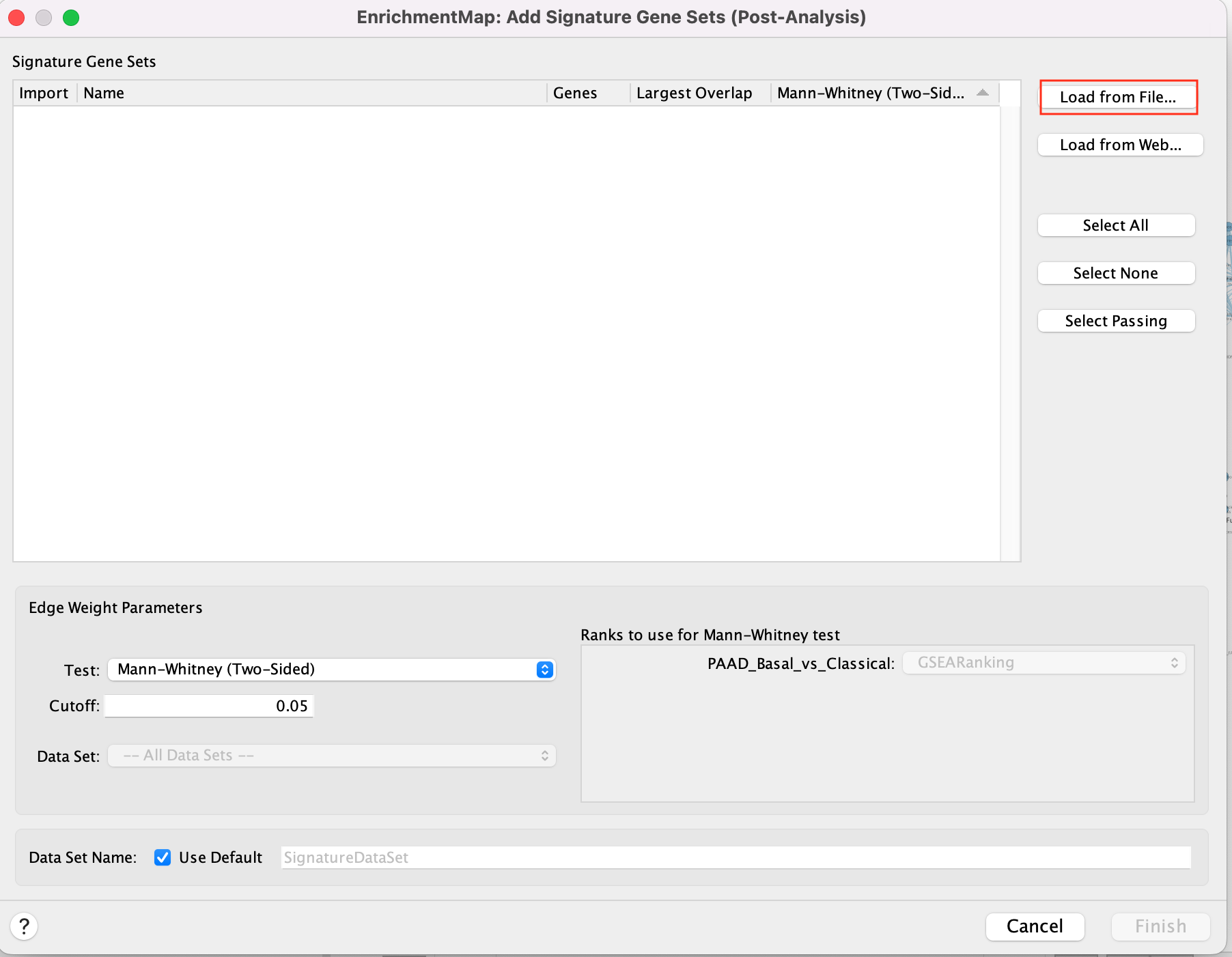
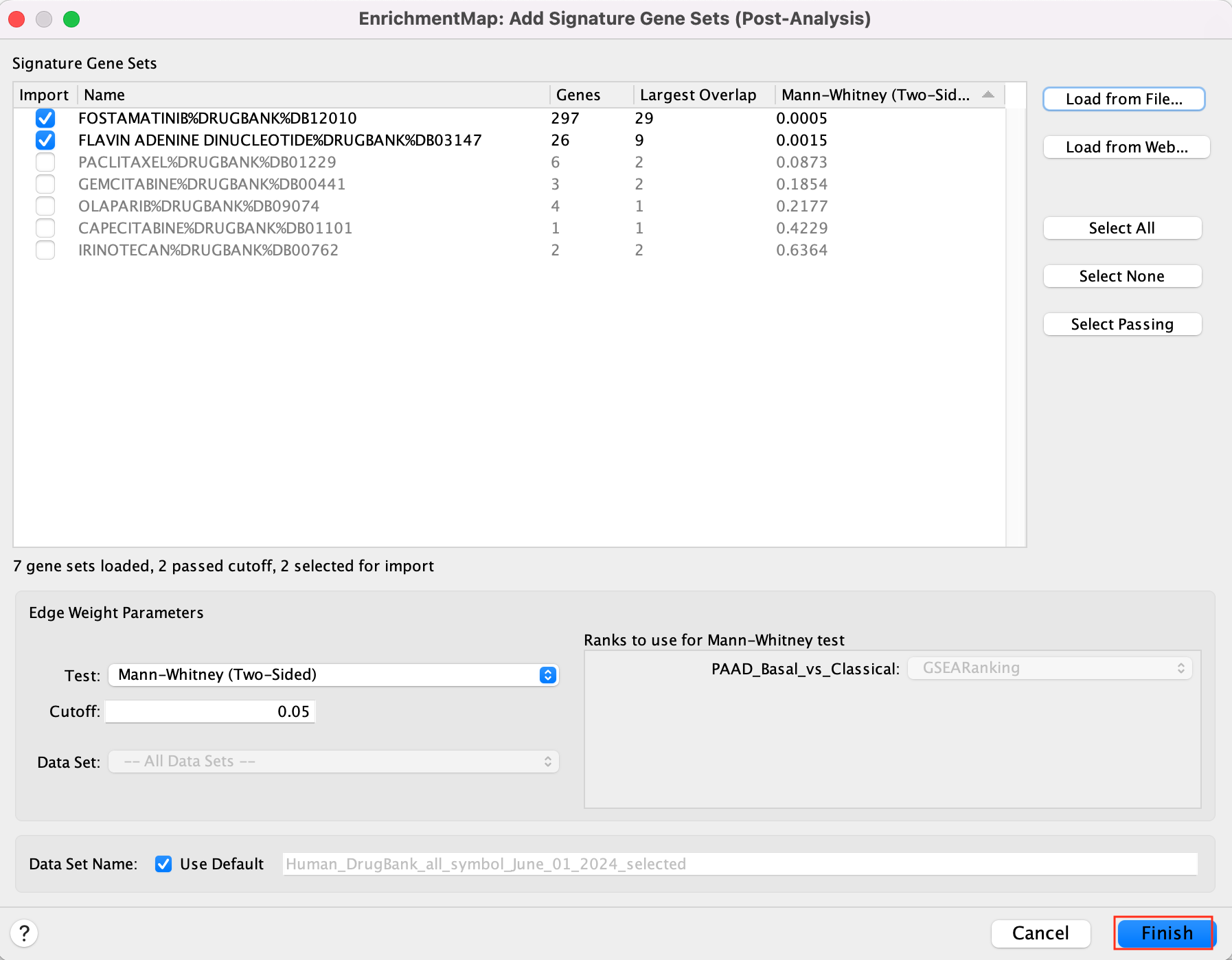
5c. Click on “Finish”.
Two additional nodes are now added to the network and visible as grey diamonds.
Dotted orange edges represent their overlap with the nodes of our network.
These additional nodes represent gene targets of some approved drugs and these genes are either specific of the basal type (dotted orange edges connected to red nodes) or specific of the classical type (dotted orange edges connected to blue nodes).
The remaining five drugs that do not pass the threshold in this map are other drugs currently used in treatment of pancreatic cancer.
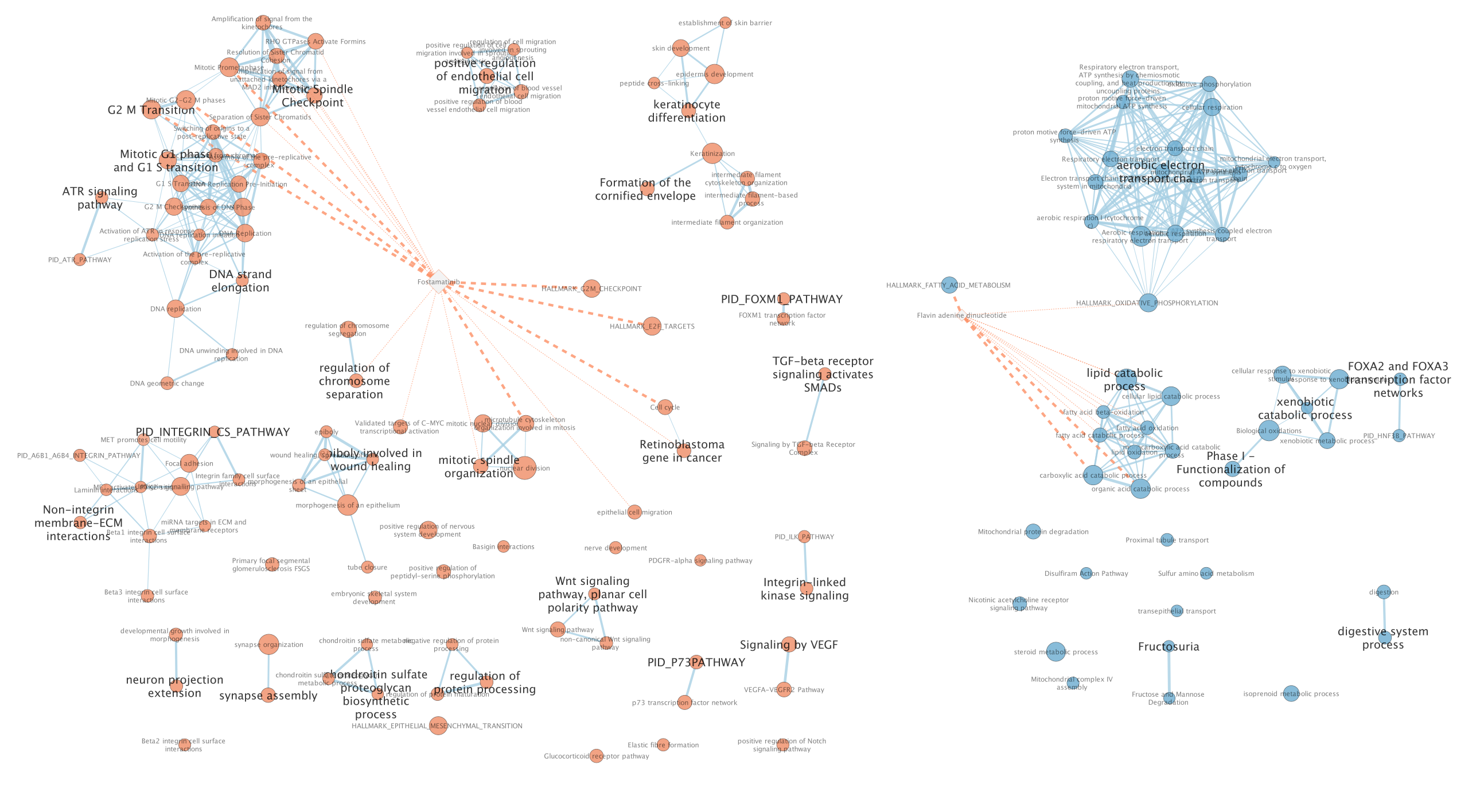
more info using this link: https://enrichmentmap.readthedocs.io/en/latest/PostAnalysis.html
Exercise 3 - Autoannotate the Network
Step 6
By default, Enrichment map will Auto-annotate the network with cluster labels.
The Apps WordCloud, ClusterMaker and Autoannotate have to be installed. (they should have been installed during the pre-workshop set up)
if you ran step 5,
delete the drug targets diamond nodes and associated edge
before performing step 6:
* select the 4 nodes and
associated dotted orange edges by browsing the mouse and
* click
“delete” on your keyboard or
* in the Cytoscape menu, ‘Edit’,
‘Delete Selected Nodes and Edges’.
Alternately, in the Enrichment Map Input Panel in the Datasets box, un-select “Human_Drugbank_approved_symbol_June_01_2024_selected” to hide the post analysis nodes.
The “annotations” are hidden but the node of each computed cluster that has the most significant FDR value is shown with a larger node label.
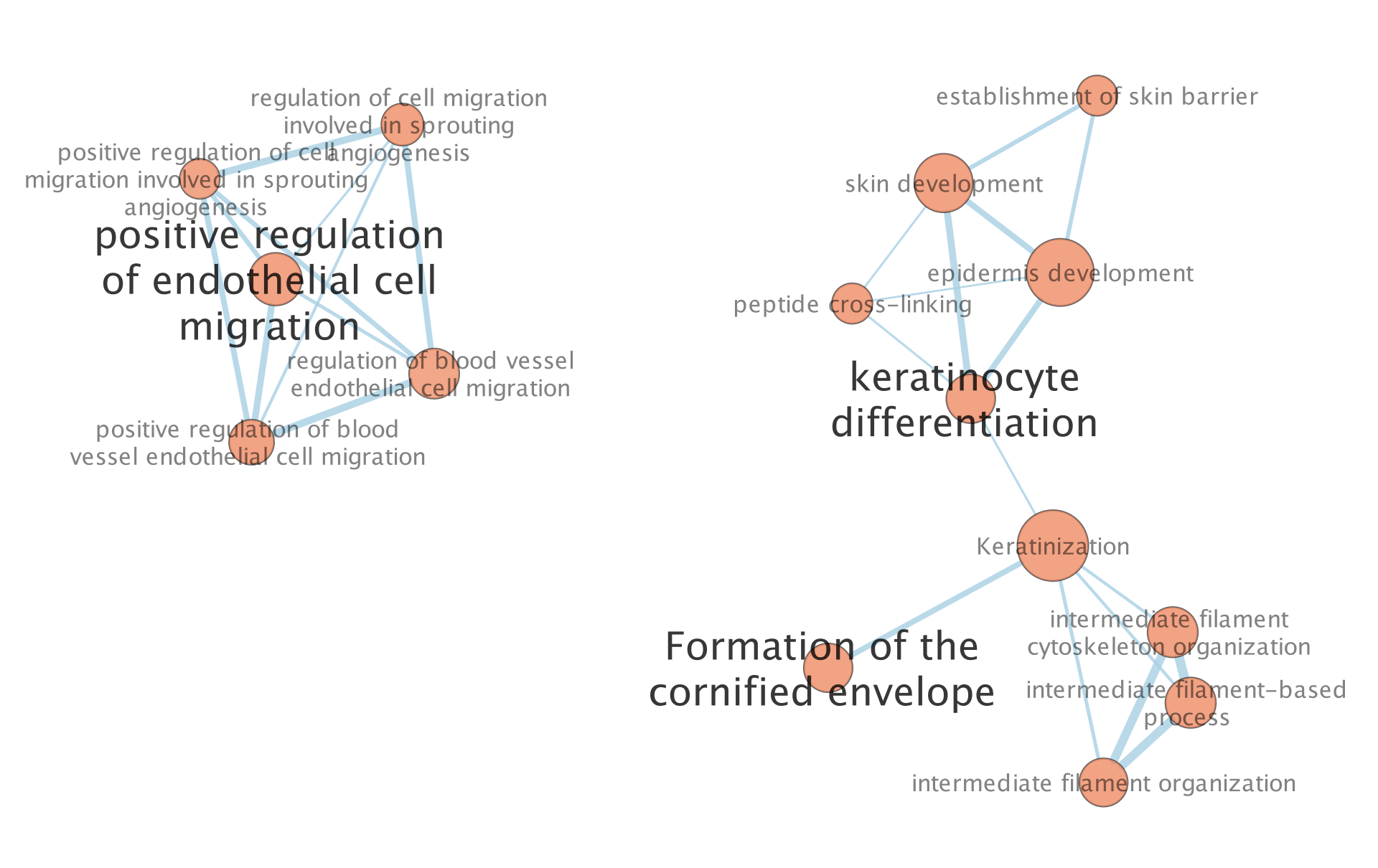
6a. To modify these precomputed annotations find the Auto annotate display panel on the right or Auto annotate input panel on the left. The right panel will contain all the different settings you can set for the annotations. By default the annotations and their labels are hidden. The left panel allows you to see all the different clusters and their labels. You can select one of many of them, change their labels or recompute the clusters with predefined clusters or one of many avaialble methods amoungst other settings. See the docs for all the available features.
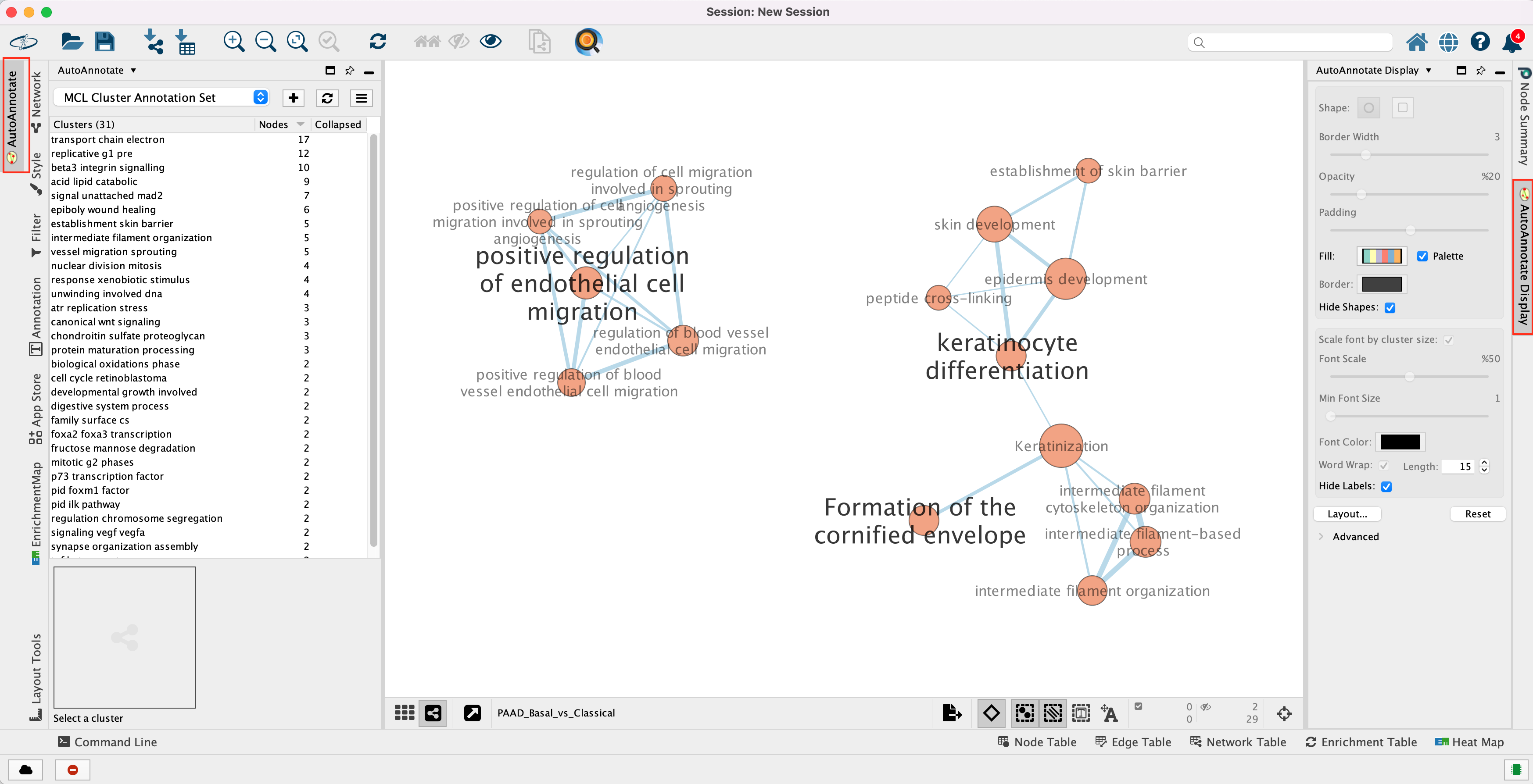
Unhide labels and shapes to see the underlying annotation for the network.
The network is now subdivided into clusters that are represented by ellipses. Each of these clusters are composed of pathways (nodes) interconnected by many common genes. These pathways represent similar biological processes. The app WordCloud take all the labels of the pathways in one cluster and summarize them as a unique cluster label displayed at the top of each ellipse.
Tip 1: further editing and formatting can be
performed on the AutoAnnote results using the AutoAnnotate
Display in the Results Panels located at the right side of
the window.
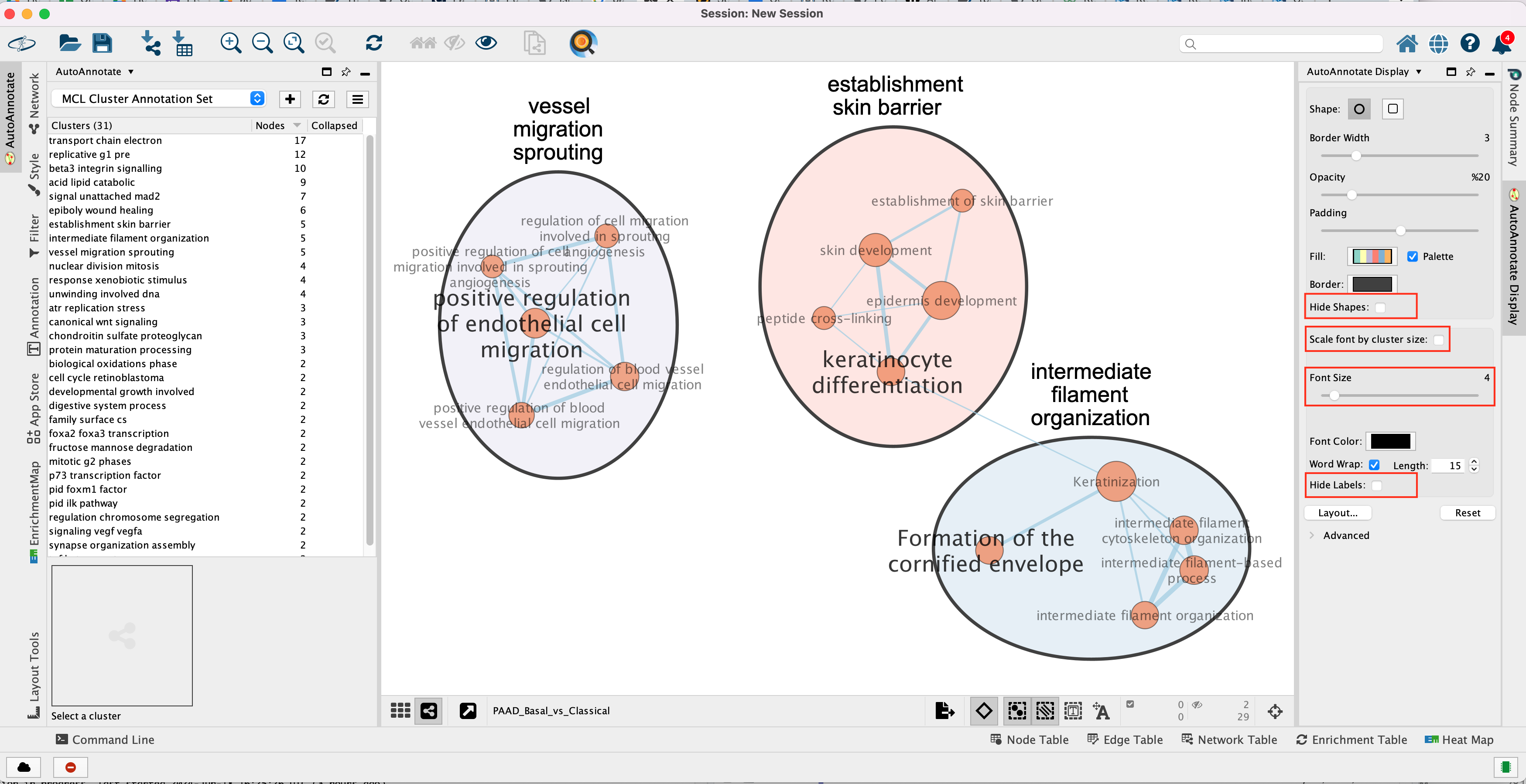
For example, it is possible to change Ellipse to
Rectangle, uncheck Scale font by cluster size and increase the
Font Scale using the scaling bar. It is also possible to reduce
the length of the cluster label by checking the “Word Wrap” option.
Tip 2: The AutoAnnotate window on the left side in Result Panel contains the list of all clusters. Clicking on a cluster label will highlight in yellow all nodes in this cluster. It is then easy to move the nodes using the mouse to avoid cluster overlaps.
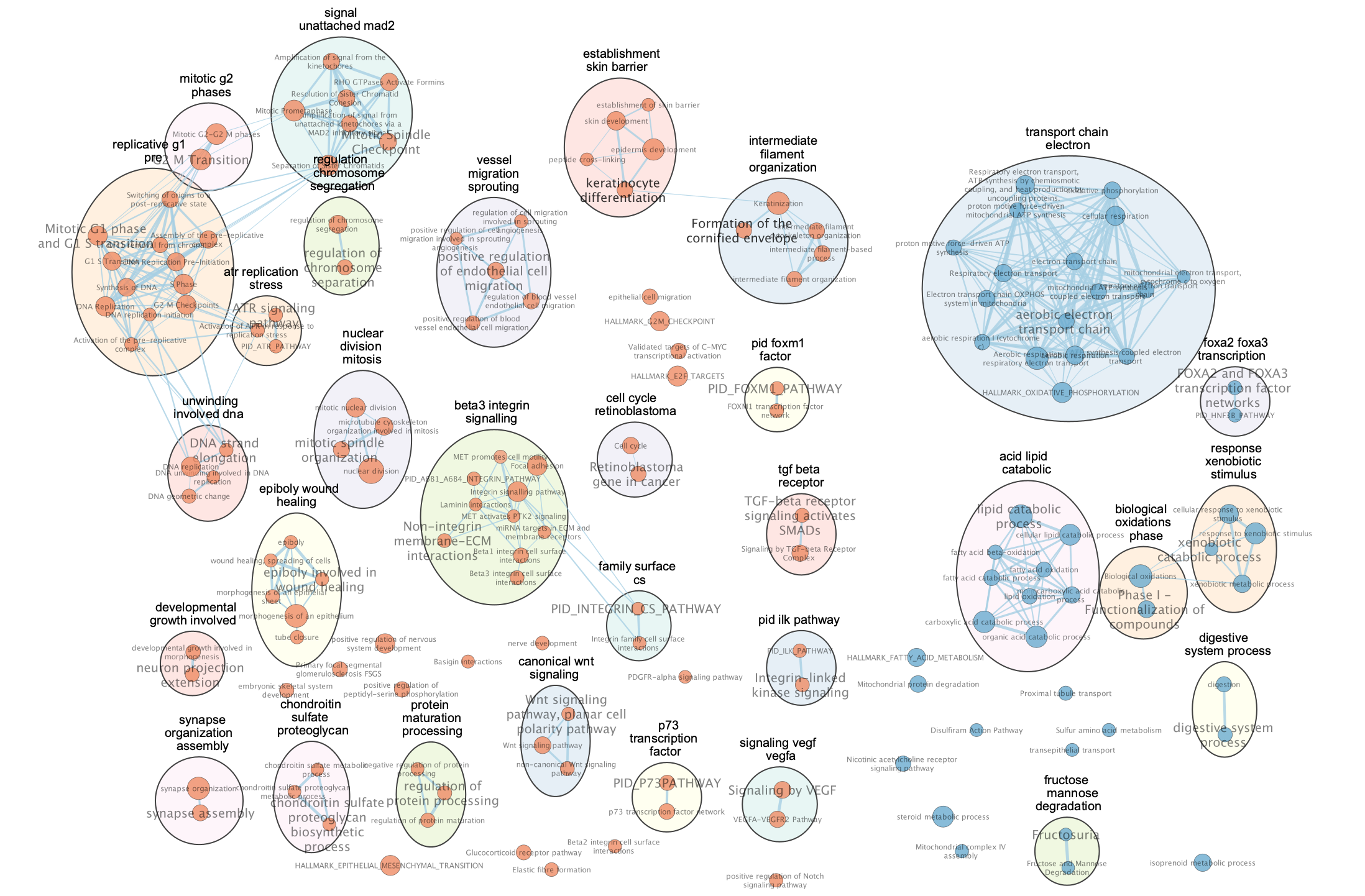
Exercise 4 (Optional) - Explore results in GeneMANIA or STRING
Each node in the Enrichment map represents a biological process or pathway. It consists of a collection of genes. Often we want to know how the genes in that group interact. There are many different ways you can investigate the underlying interactions for the given group. Some involve searching online databases and others are directly integrated into cytoscape.
- GeneMANIA - an integrative database of gene connections including co-expression, protein interactions, genetic interactions, pathways and more. Cytoscape App
- String - an integrative database of gene connections including co-expression, protein interactions, genetic interactions, pathways and more. Cytoscape App
- Pathway Commons - a intergrative database of pathways. (There is a beta feature in EM to show your pathway in the painter app, a pathway common web page that overlays your expression data on the given pathway. Still in beta testing and requires expression data to work correctly so won’t work for this example)
Step 7
Visualize genes in a pathway/node of interest using the apps STRING and GeneMANIA. This will create a protein-protein interaction network using the genes included in the pathway. Note: We will go more in depth into GeneMANIA in module 5
7a: Click on an individual node of interest.
For this example, you could use xenobiotic metabolic process.
If you are unable to locate xenobiotic metabolic process, type “xenobiotic metabolic process” in the search box (quotes are important). The selected node appears yellow (or highlighted) in the network. If you have annotated your network, it should be included in the response xenobiotic stimulus cluster.
7b: Right Click on the node of interest to diplay the option menu. Select Apps,–> EnrichmentMap - Show in STRING
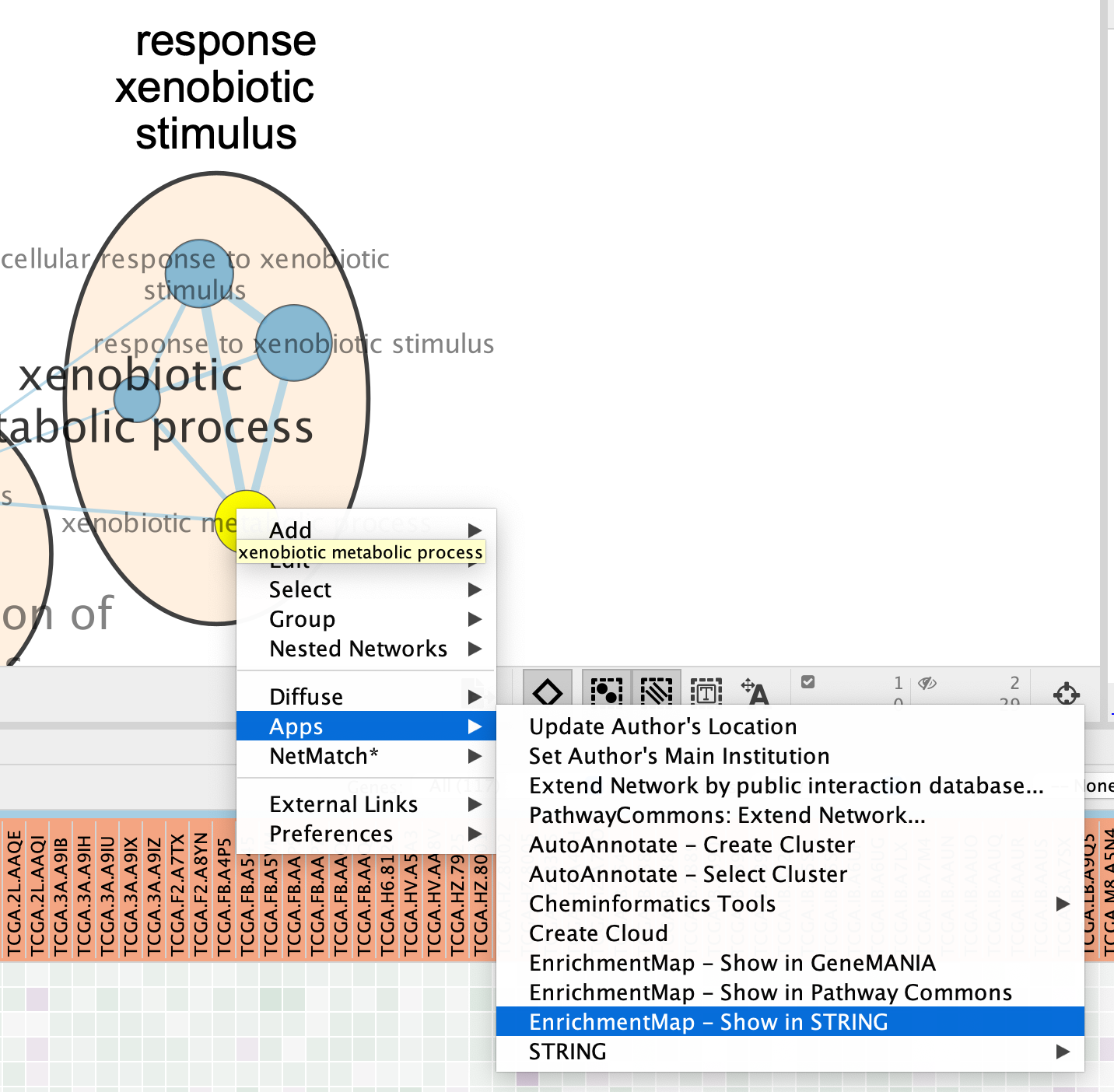
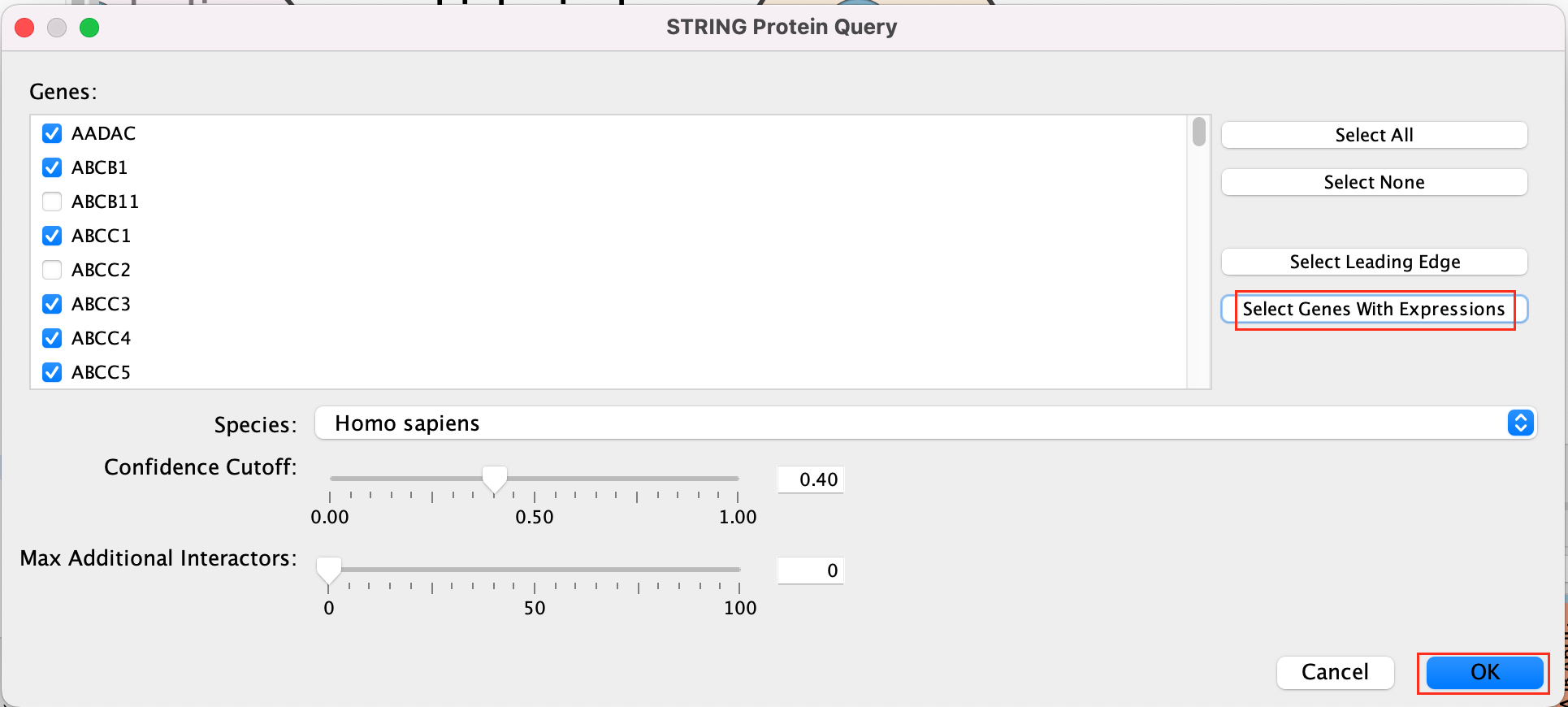
Patience. :) . It might take a few seconds for the String Protein Query window to open.
- A STRING Protein Query box appears.
- Select Select genes with expression.
- Click on OK.
- The resulting network will look something like this.

Explore the features and data of each Cytoscape app.
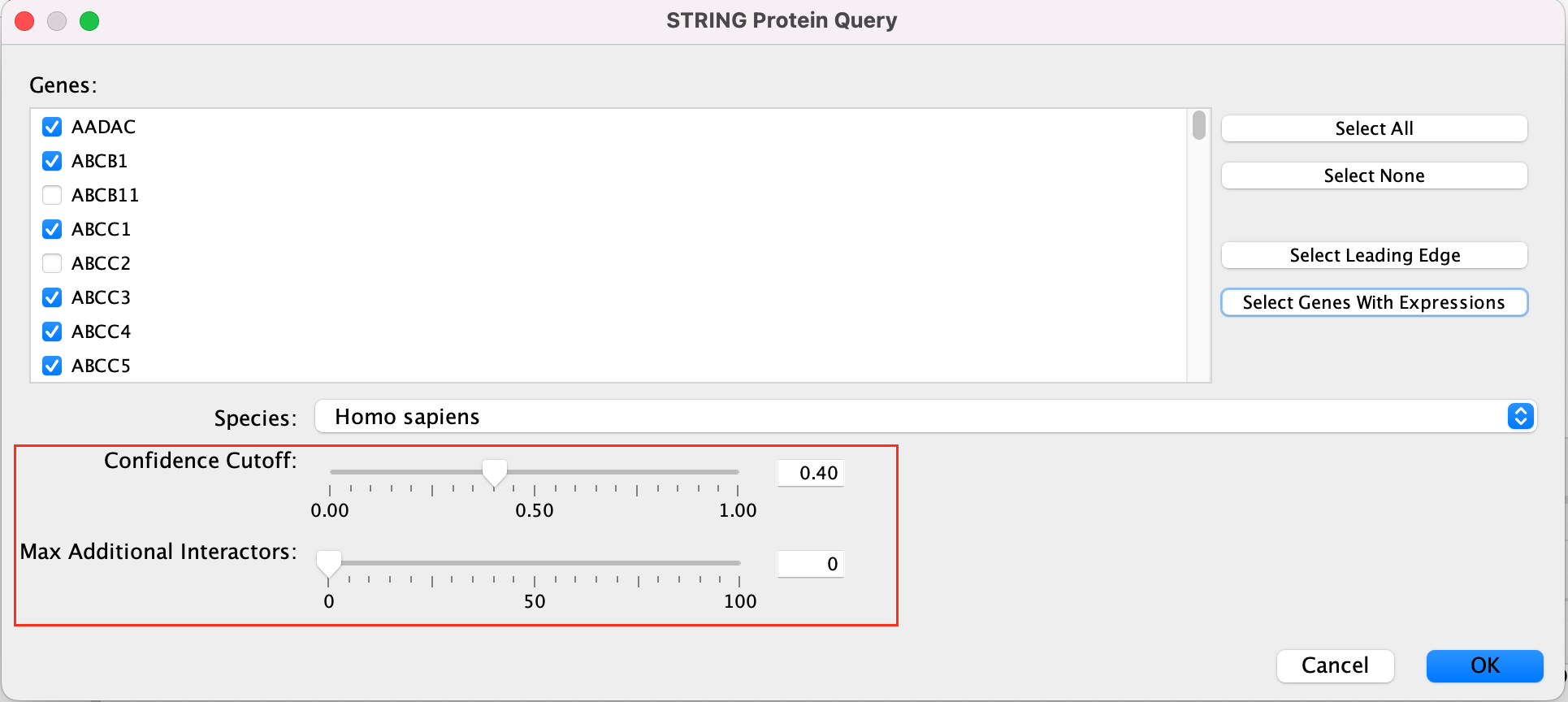
What happens
to the network if you change the initial parameters like Confidence
cutoff or Max Additional interactors
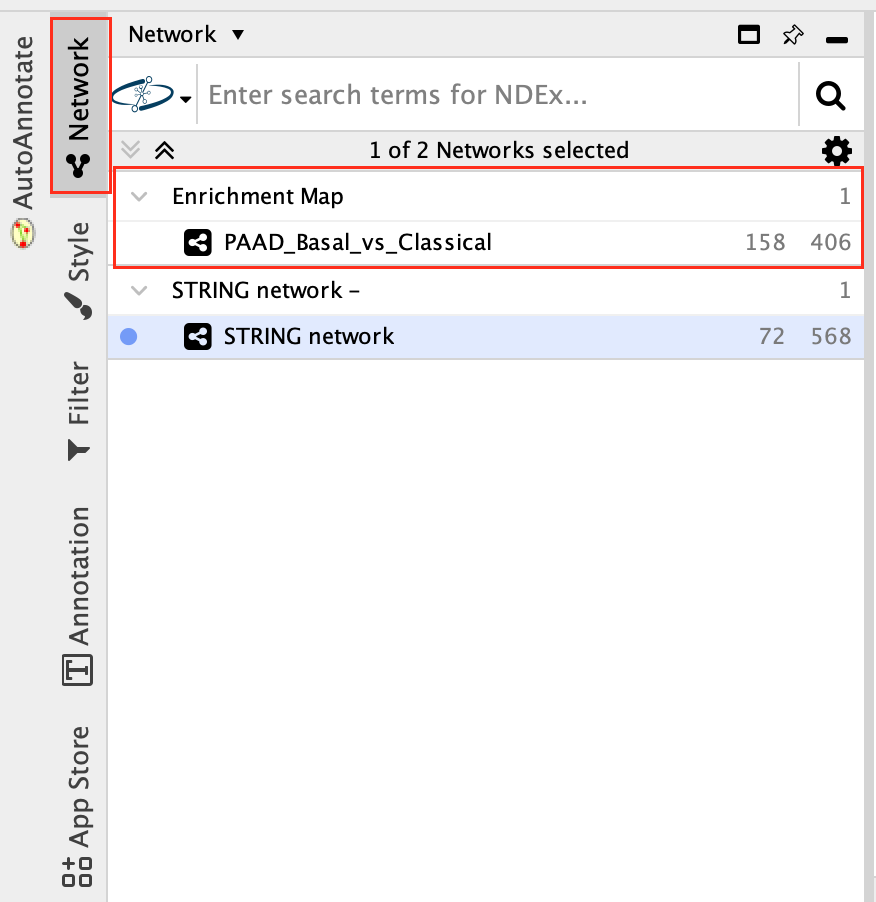
7c:Go back to enrichment map network.
- In Control Panel (left side of the window), select the “Network” tab and click on the Enrichment Map network as shown in below screenshot.
7d: Search again for the node labelled xenobiotic metabolic process (if it is not still selected) as in Step 7a.
- Right Click on the node of interest to diplay the option menu. Select Apps,–> EnrichmentMap - Show in GeneMANIA
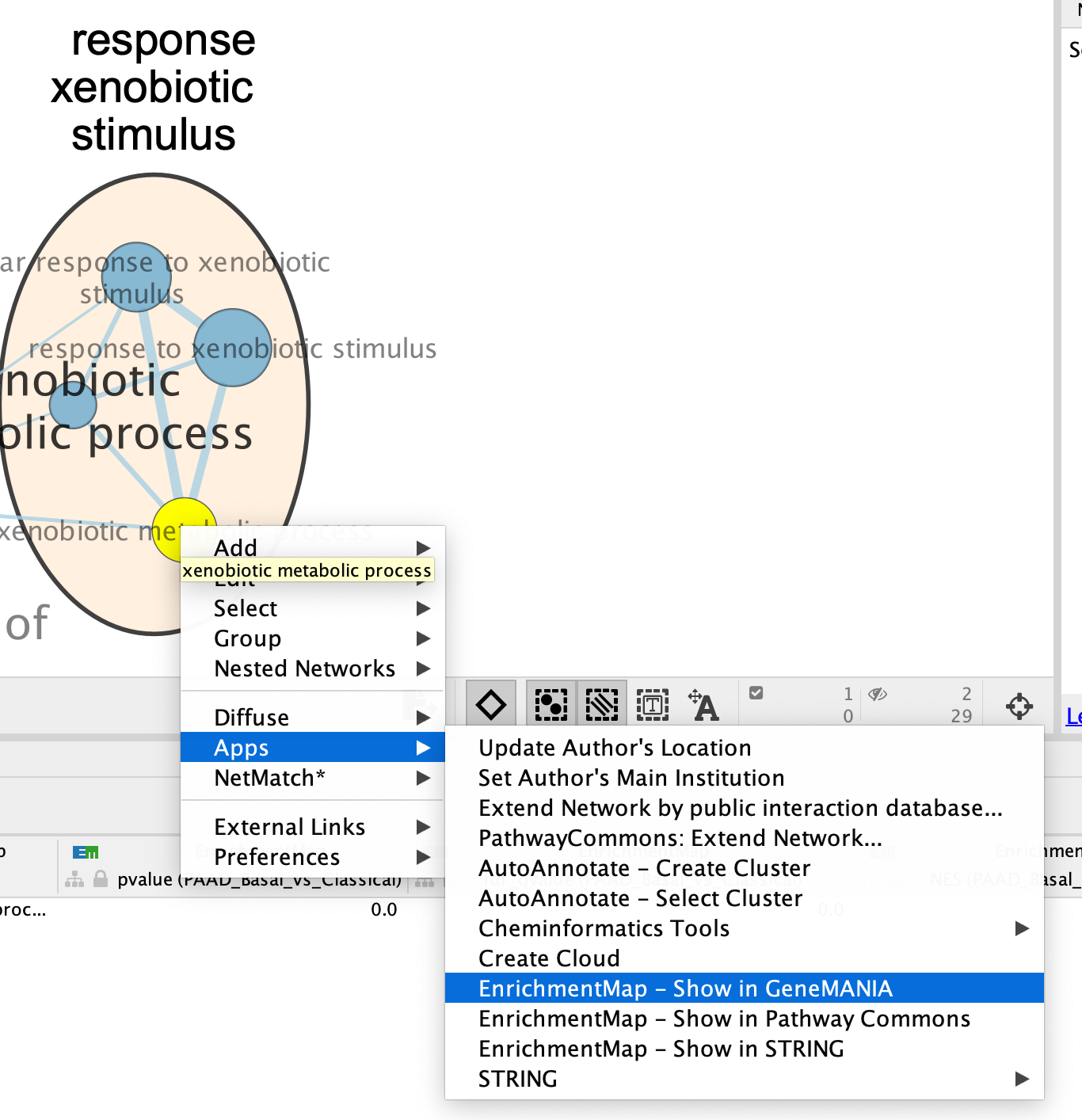
- A GeneMANIA Query box appears.
- select Select genes with expression.
- Click on OK.
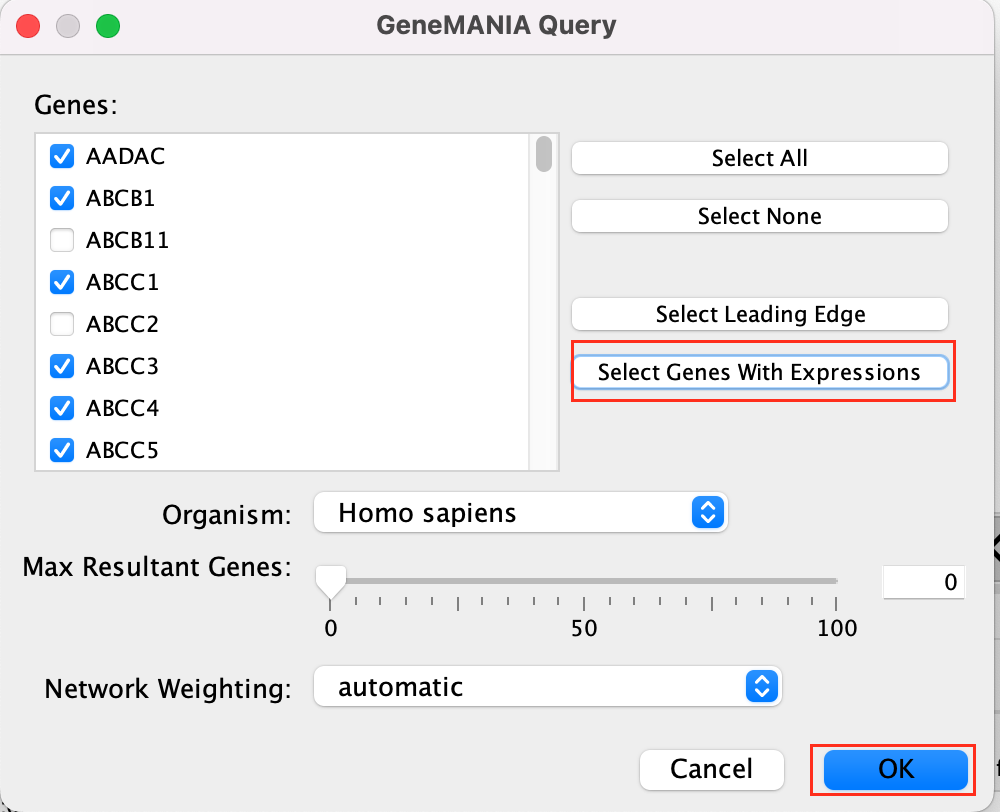
- A pop up will appear indicating that it is currenlty querying GeneMANIA
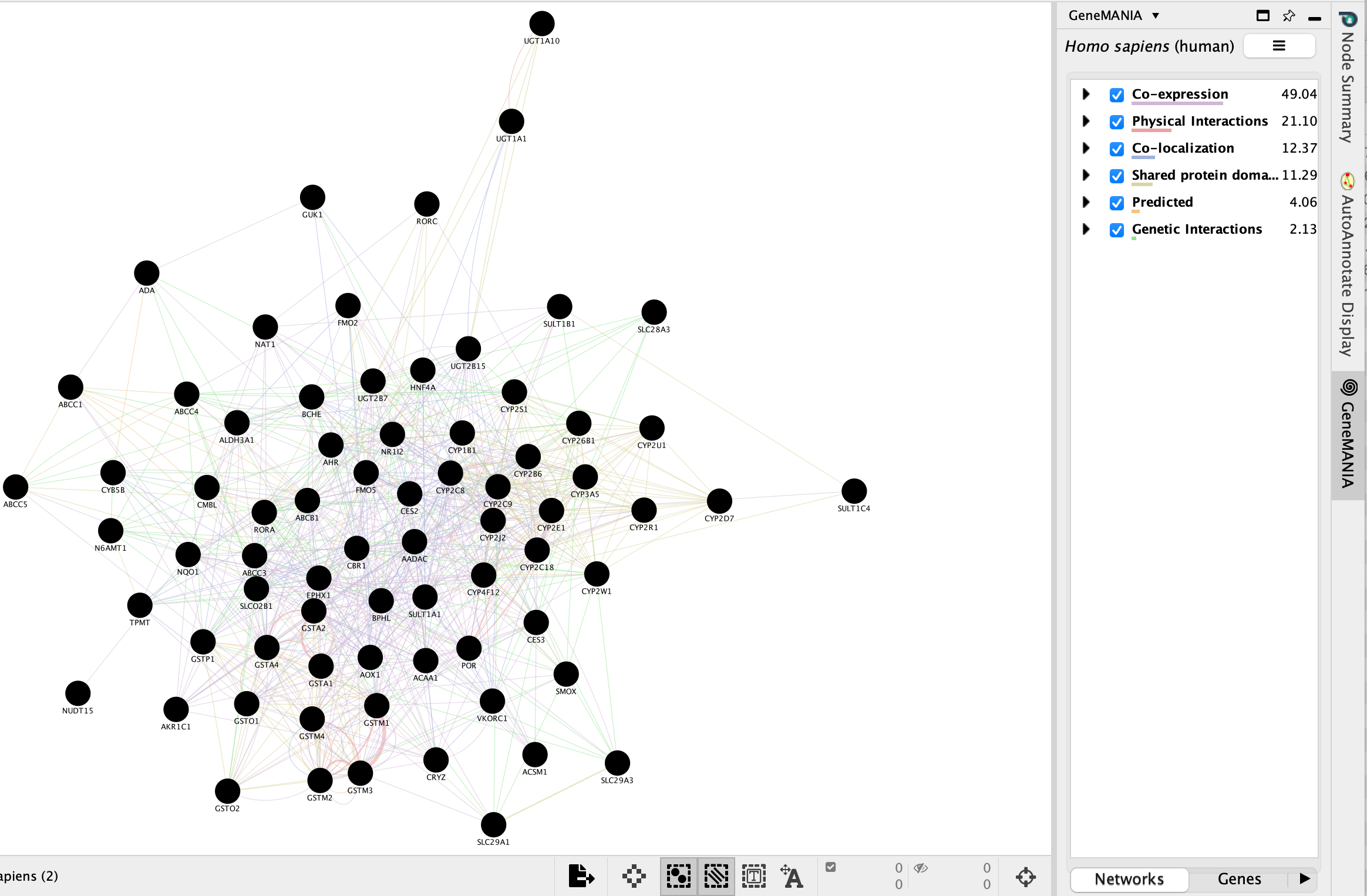
- The resulting network will look similiar to the below screenshot.
It is possible to view gene expression data for the nodes in the STRING network. See the section https://enrichmentmap.readthedocs.io/en/latest/Integration.html and try it out after the workshop.
SAVE YOUR SESSION FILE!
Bonus - Automation.
Run analysis directly from R for easy integration into existing pipelines.
Instead of creating an Enrichment map manually through the user interface you can create an enrichment map directly using the RCy3 bioconductor package or through direct rest calls with Cytoscape cyrest.
Follow the step by step instructions on how to run from R here - https://risserlin.github.io/CBW_pathways_workshop_R_notebooks/create-enrichment-map-from-r-with-gsea-results.html
First, make sure your environment is set up correctly by following there instructions - https://risserlin.github.io/CBW_pathways_workshop_R_notebooks/setup.html