Module 5 Lab: GeneMANIA (web version)
This work is licensed under a Creative Commons Attribution-ShareAlike 3.0 Unported License. This means that you are able to copy, share and modify the work, as long as the result is distributed under the same license.
By Veronique Voisin
Goal of this practical lab
Create GeneMANIA networks starting from a single gene to predict its function or starting from a gene list. Explore and understand the main output features of GeneMANIA such as the network composition or the enriched functions.
This practical consists of 3 exercises. You can choose to do these exercises using the questions as your only guide (section ‘QUESTIONS AND STEPS TO FOLLOW) - or see the following pages for the step-by-step checklist to find the answers (section ’ANSWERS: DETAILED STEPS AND SCREENSHOTS’).
Before starting the exercises,download the files:
Right click on link below and select “Save Link As…”.
Place the file in your CBW work directory in the corresponding module directory.
Network layouts are flexible and can be rearranged. What you see when you perform these exercises may not be identical to what you see in the tutorial, or what you have seen other times that you have performed the exercises. Exact layouts and predictions can also be affected by updates to the networks database that GeneMANIA uses. However it is expected that the network weights and predicted genes will be similar to those shown here.
EXERCISE 1: QUESTIONS AND STEPS TO FOLLOW
Imagine that you are interested in exploring the function of the human GRN gene: GRN returned as the strongest hit from your omics experiment but not many information about this gene is available in functional databases. Use GeneMANIA to identify its predicted function as well as potential interaction partners.
Skills:
- GeneMANIA Single Gene search; Navigating Search Results;
- Exploring available Genes features;
- Rerun a new analysis using a single gene or multiple genes query from the network.
STEPS
Go to GeneMANIA’s homepage at http://www.genemania.org/
In the search window, ensure that the model organism is set to Homo sapiens
 .
.Enter the following gene: GRN
Click on the search icon
 and wait for the results.
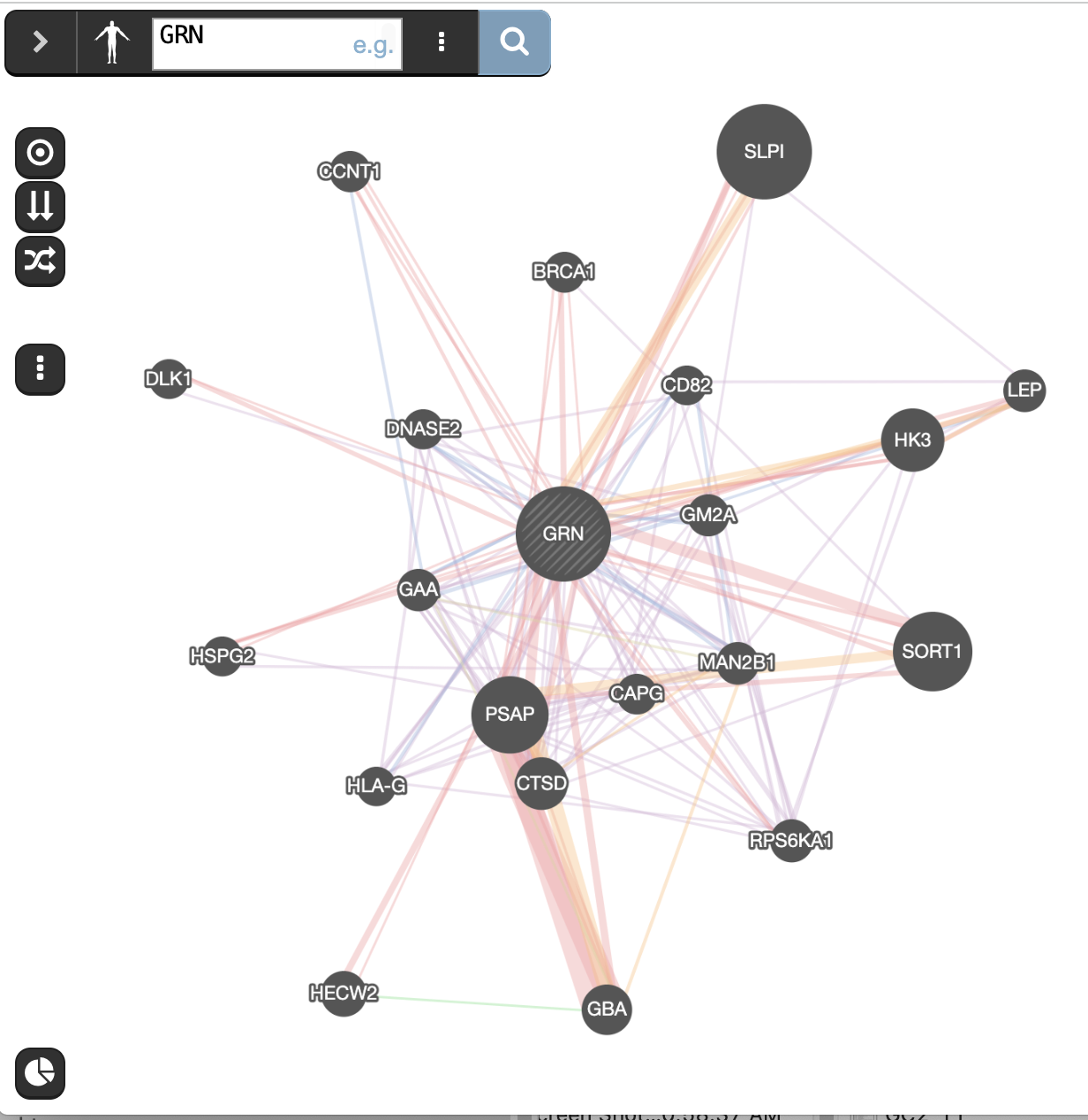
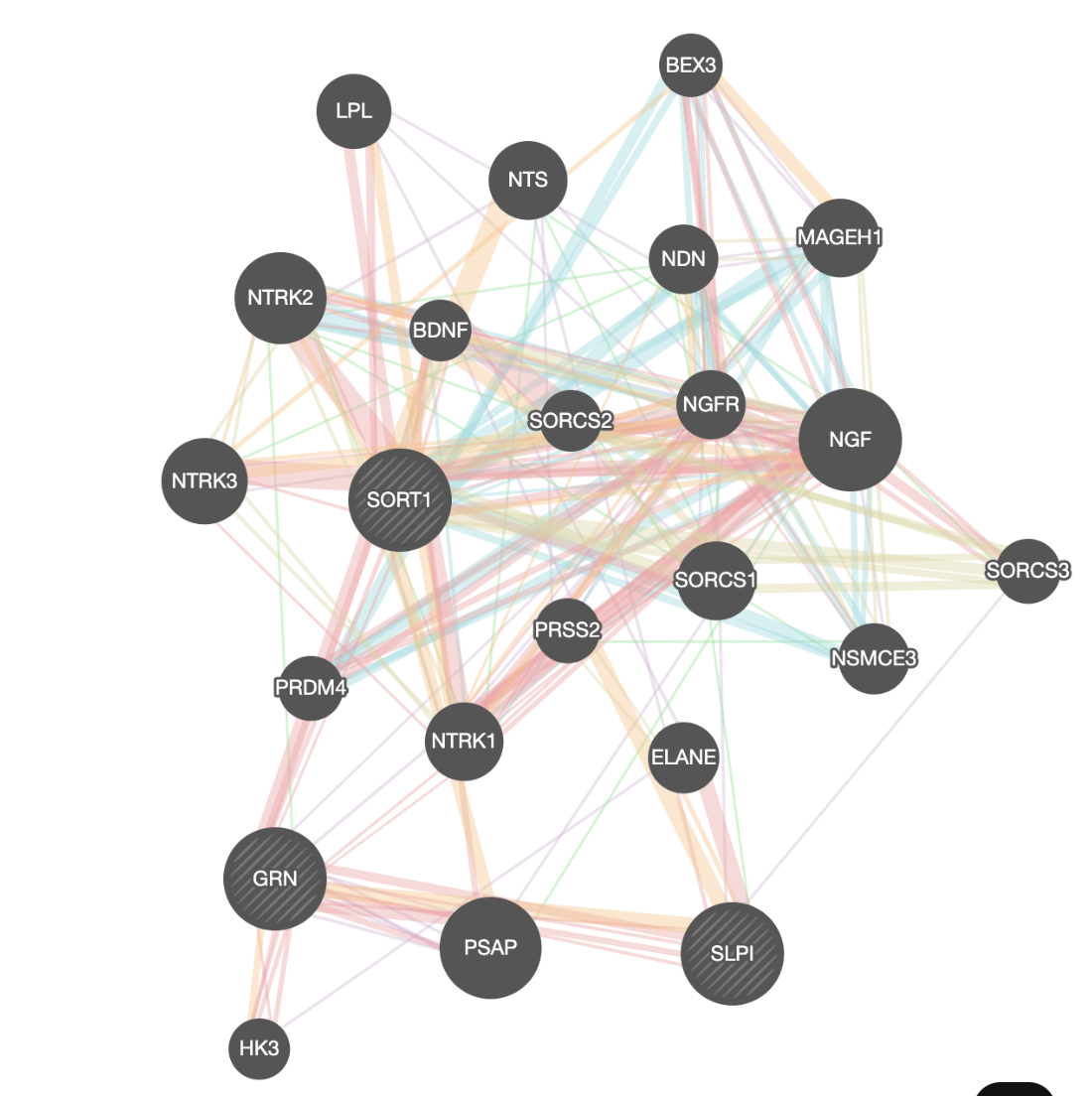
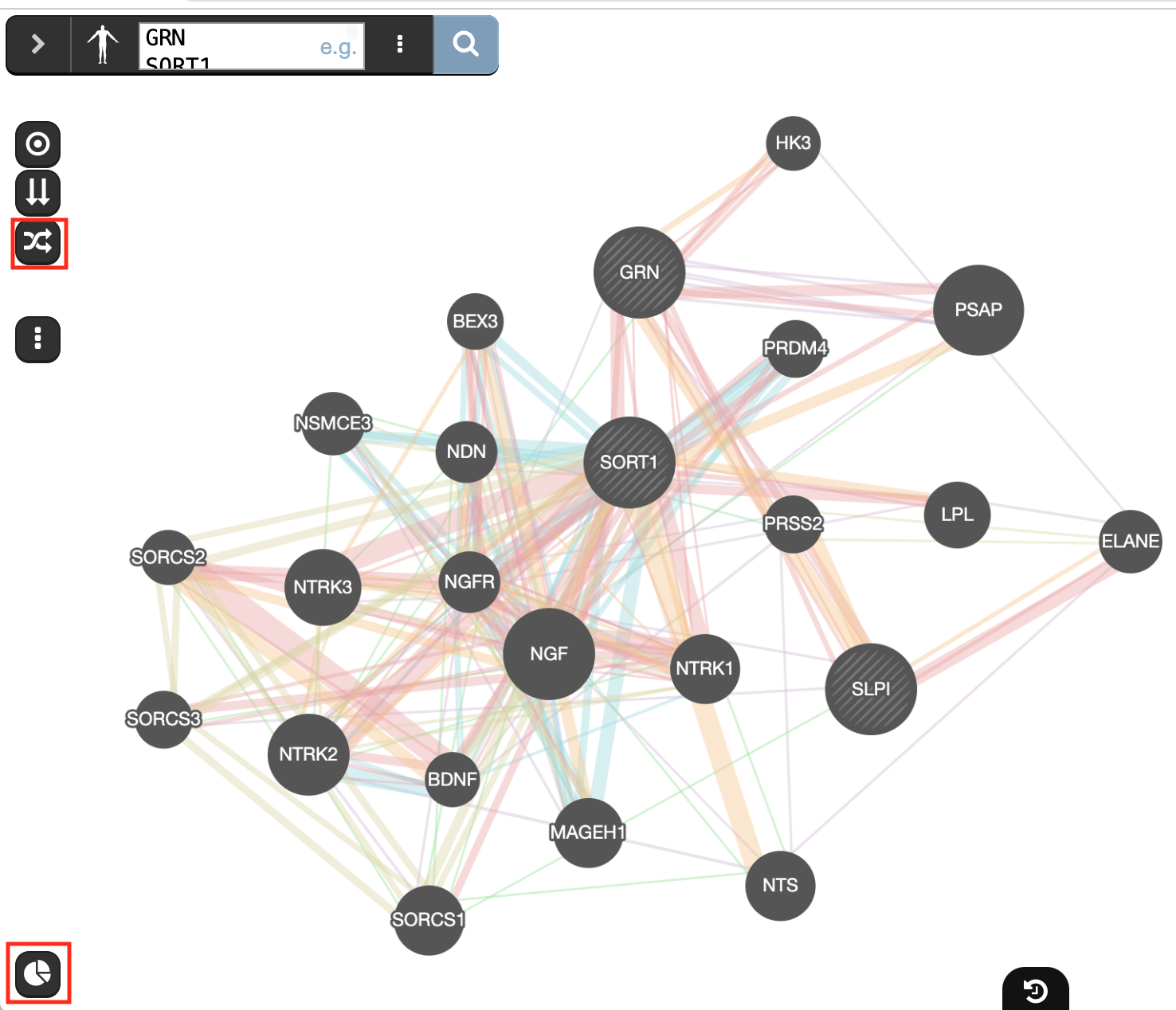
and wait for the results.When your search results load, examine the network. Query genes are indicated with stripes, related genes added by GeneMANIA are represented in black, and colored links represent the interactions that connect the nodes (genes).
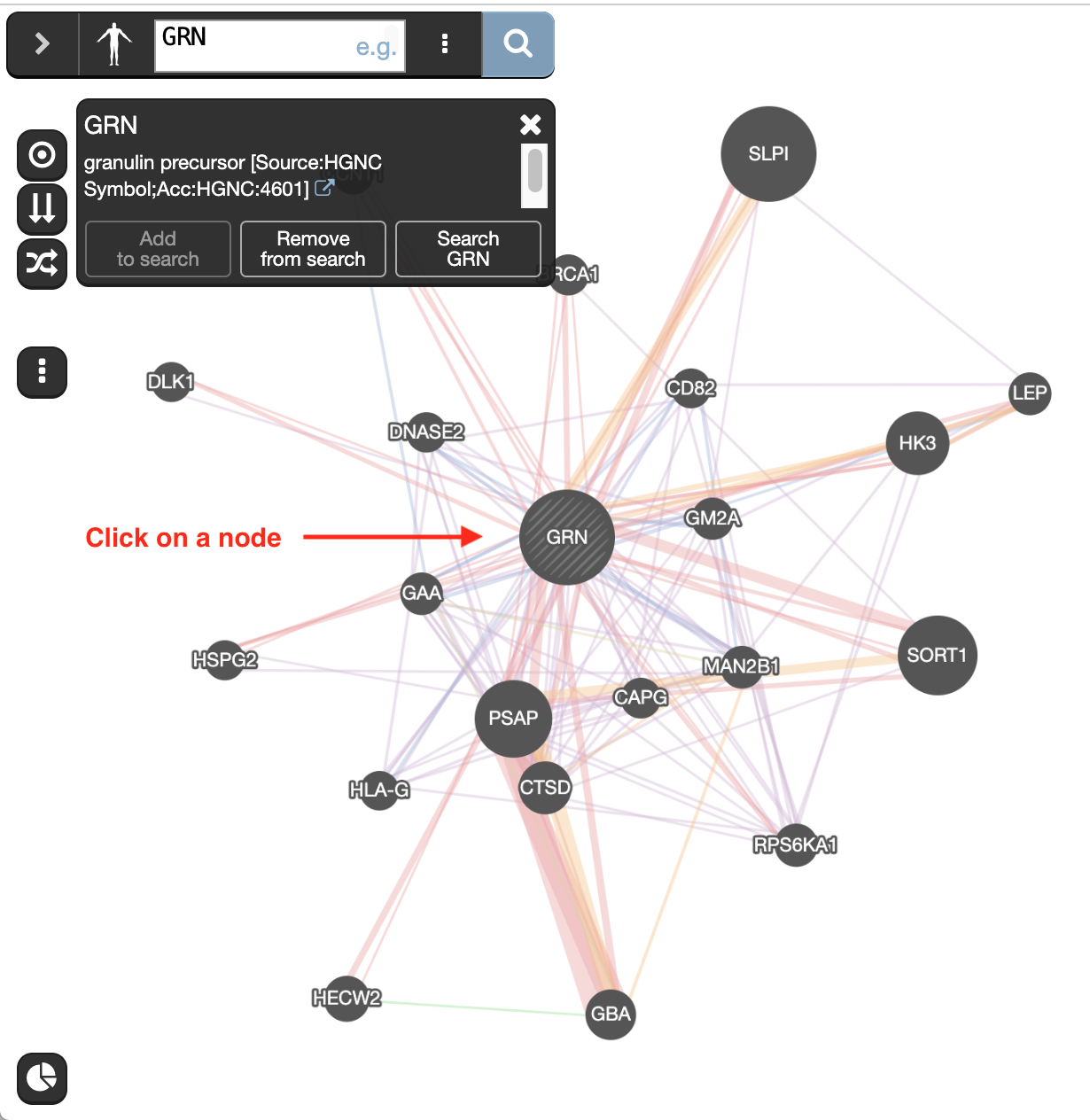
Clicking on a node gives information about its name, the possibility to add or remove this gene from the search (if the gene was not part of the initial search remove from search will be grayed out) or run a search with this gene only.
- Click on the GRN node and explore the displayed information.
Locate the Functions summary tab (bottom left icon
 ).
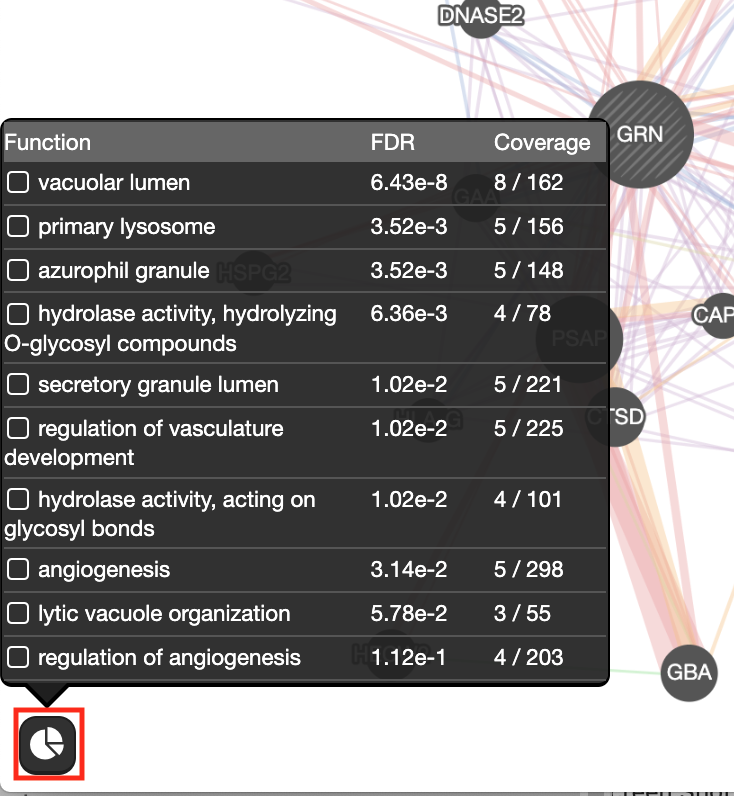
).- What are the functions significantly associated with this network?
- GRN is the central node of this network: which function would you predict for GRN?
- How well did GeneMANIA perform (hints: use GeneCards (http://www.genecards.org/) , PubMed (http://www.ncbi.nlm.nih.gov/pubmed/))?
- What are the functions significantly associated with this network?
Locate the gene with the strongest association with GRN.
The larger the node in this network, the stronger its association with the query. Node size is correlated to its GeneMANIA score.
- Re-run the analysis with added genes SORT1, SLPI to the search.
- Which functions are associated with this new network ?
- Which functions are associated with this new network
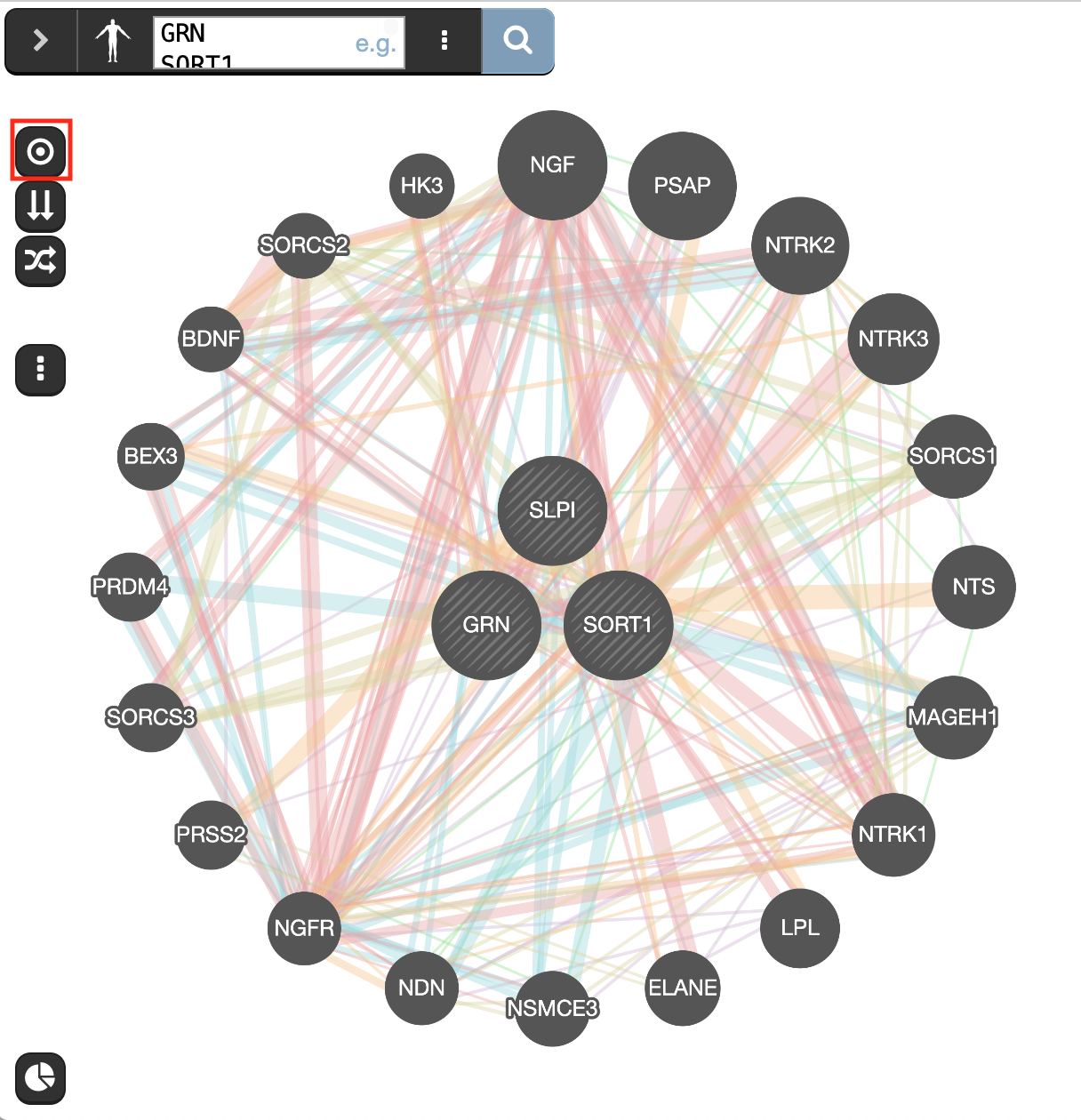
- On the left side of the window are located icons that we haven’t yet explored. The first 3 buttons activate different network layouts. Try
- the circular
 ,
, - the aligned
 , and
, and - the force_directed
 layouts.
layouts.
- the circular
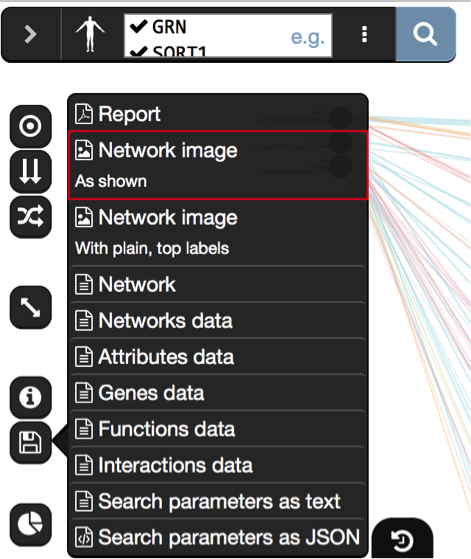
- Choose your favorite layout and
- save the network as an image using the Network image As Shown option from the save menu
 .
.
- The menu can be opened by clicking on the 3 dots icon on the left hand side of the window (not the three dot icon in the search bar).
- save the network as an image using the Network image As Shown option from the save menu
EXERCISE 1 ANSWERS: DETAILED EXPLANATION AND SCREENSHOTS
Exercise 1 - STEP 7
Question What are the functions significantly associated with this network?
Answer the list of the functions associated with the network are listed in the above screenshot. “vacuolar lumen” and “primary lysosome” are the top 2 functions.
Question GRN is the central node of this network: which function would you predict for GRN?
Answer : a function related to lysosome and vacuole
Question How well did GeneMANIA perform (hints: use GeneCards (http://www.genecards.org/) , PubMed (http://www.ncbi.nlm.nih.gov/pubmed/))?
Answer
The top functions predicted by GeneMANIA for GRN were related to lysosome and vacuole. A pubmed search could confirm these results: “We experimentally verified that granulin precursor (GRN) gene, whose mutations cause frontotemporal lobar degeneration, is involved in lysosome function.” (Transcriptional gene network inference from a massive dataset elucidates transcriptome organization and gene function. Belcastro et al. Nucleic Acids Res. 2011 Nov 1;39(20):8677-88. 2011. PMID:21785136)
Exercise 1 - STEP 8
Question Locate the genes with the strongest association with GRN (thick edge).
Answer is SORT1 and SLPI
Exercise 1 - STEP 11 (save an image)
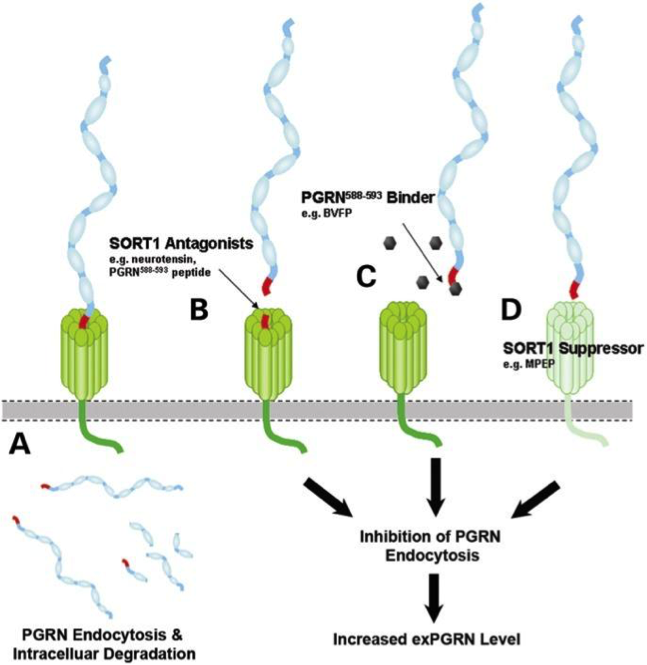
Notes about biological interpretation of the results:
A paper describing the interaction between GRN and SORT1 and demonstrates how finding related genes could be relevant for elaborating therapy:
Targeted manipulation of the sortilin–progranulin axis rescues progranulin haploinsufficiency. Lee et al. Hum Mol Genet. 2014 March 15; 23(6): 1467–1478. PMCID:PMC3929086
“Progranulin (GRN) mutations causing haploinsufficiency are a major cause of frontotemporal lobar degeneration (FTLD-TDP). Recent discoveries demonstrating sortilin (SORT1) is a neuronal receptor for PGRN endocytosis and a determinant of plasma PGRN levels portend the development of enhancers targeting the SORT1–PGRN axis. We demonstrate the preclinical efficacy of several approaches through which impairing PGRN’s interaction with SORT1 restores extracellular PGRN levels. “
EXERCISE 2: QUESTIONS AND STEPS TO FOLLOW
To start this exercise, you need to download the 30_prostate_cancer_genes.txt file and save it on your computer.
For this exercise, you are working with a list of 30 prostate cancer genes. This list can be downloaded after the workshop from the cBioPortal website (http://www.cbioportal.org/). The cBioPortal for Cancer Genomics stores genomic data from large scale, integrated cancer genomic data sets. During this exercise, you will explore the types of networks that have been used to create the GeneMANIA network from the prostate cancer gene list and you will see how changing input parameters can affect the results.
Skills:
- GeneMANIA search using a gene list;
- Navigating Search Results;
- Exploring Networks and advanced options;
- Uploading a custom network.
STEPS
Go to GeneMANIA’s homepage at http://www.genemania.org/
In the search window, ensure that the model organism is set to Homo sapiens
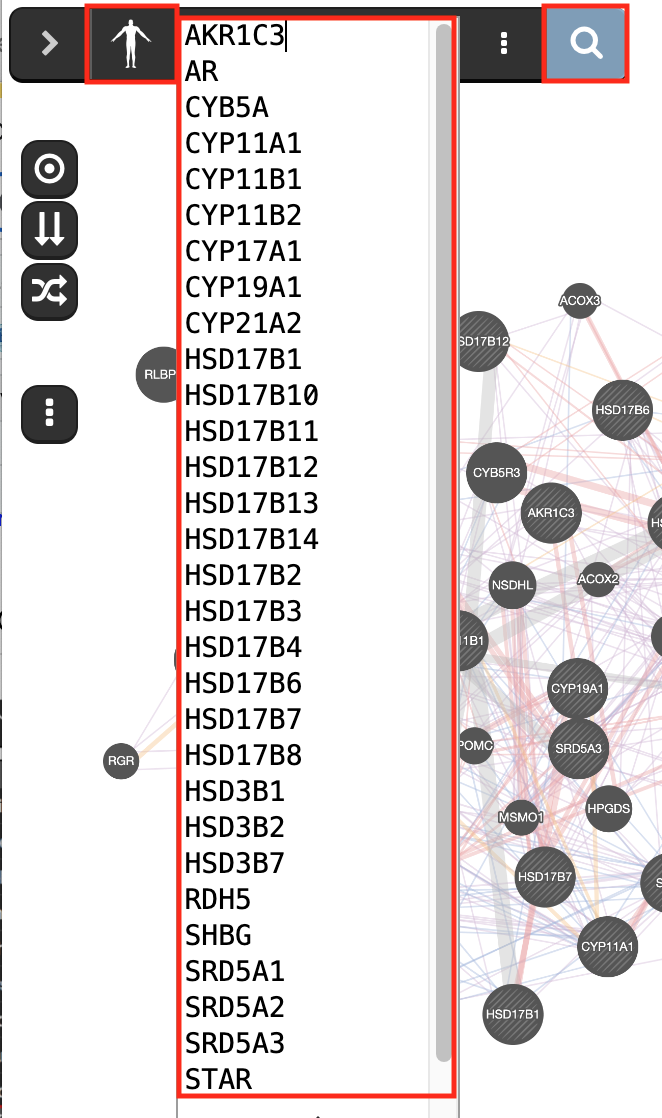
.Copy and paste genes in the file 30_prostate_cancer_genes.txt.
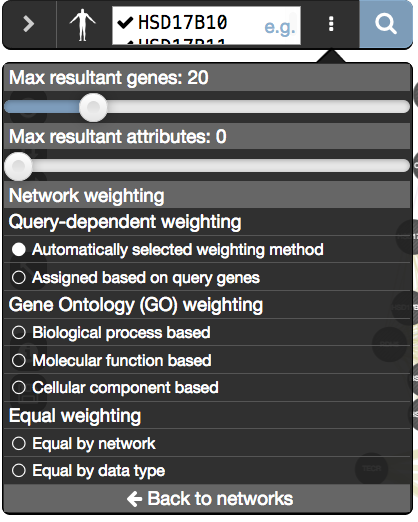
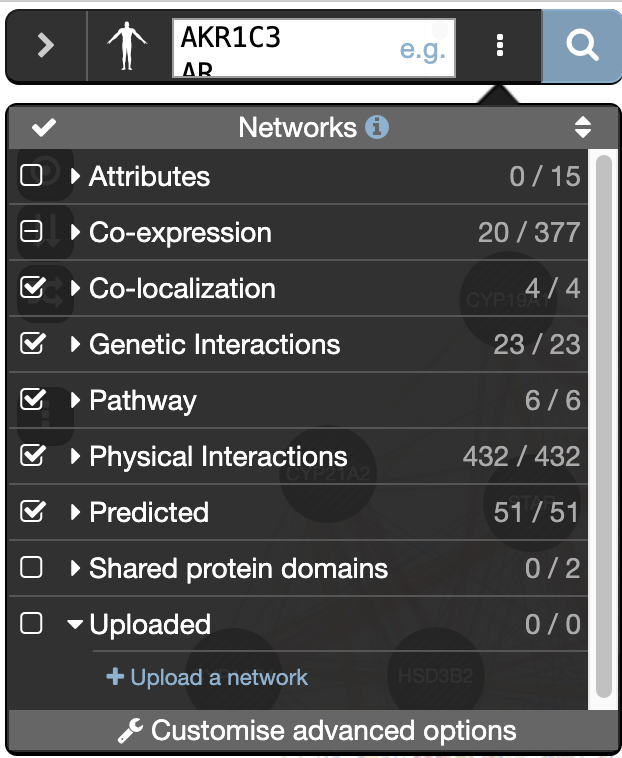
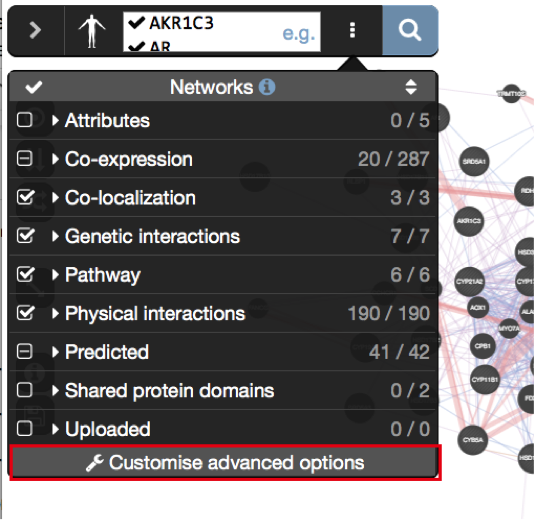
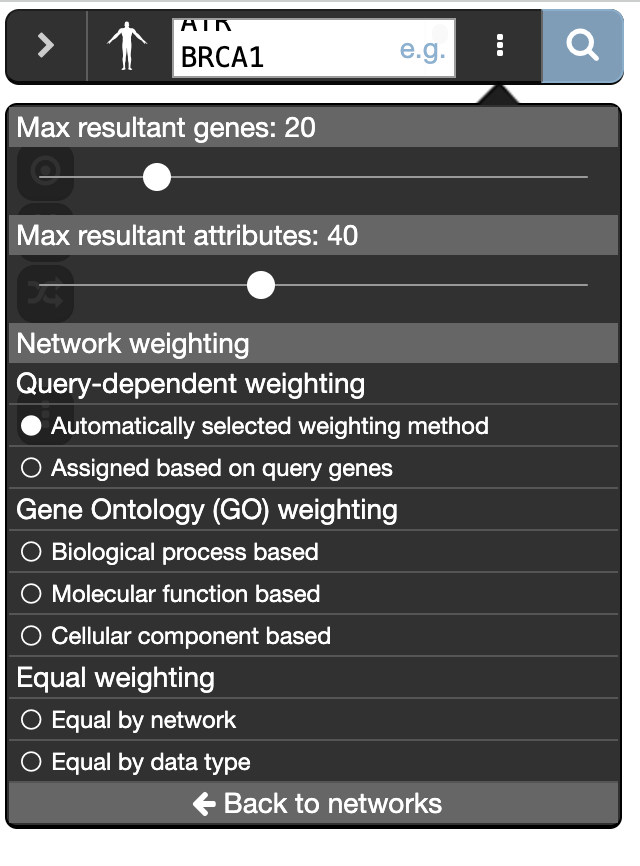
- Make sure that the parameter ‘Max resultant genes’ is set to 20 by clicking on the 3 menu buttons at the right side of the search box and selecting ‘Customize advanced options’.
- Set ‘Max resultant attributes’ to 10.
- Make sure that the parameter ‘Max resultant genes’ is set to 20 by clicking on the 3 menu buttons at the right side of the search box and selecting ‘Customize advanced options’.
Click on the search icon
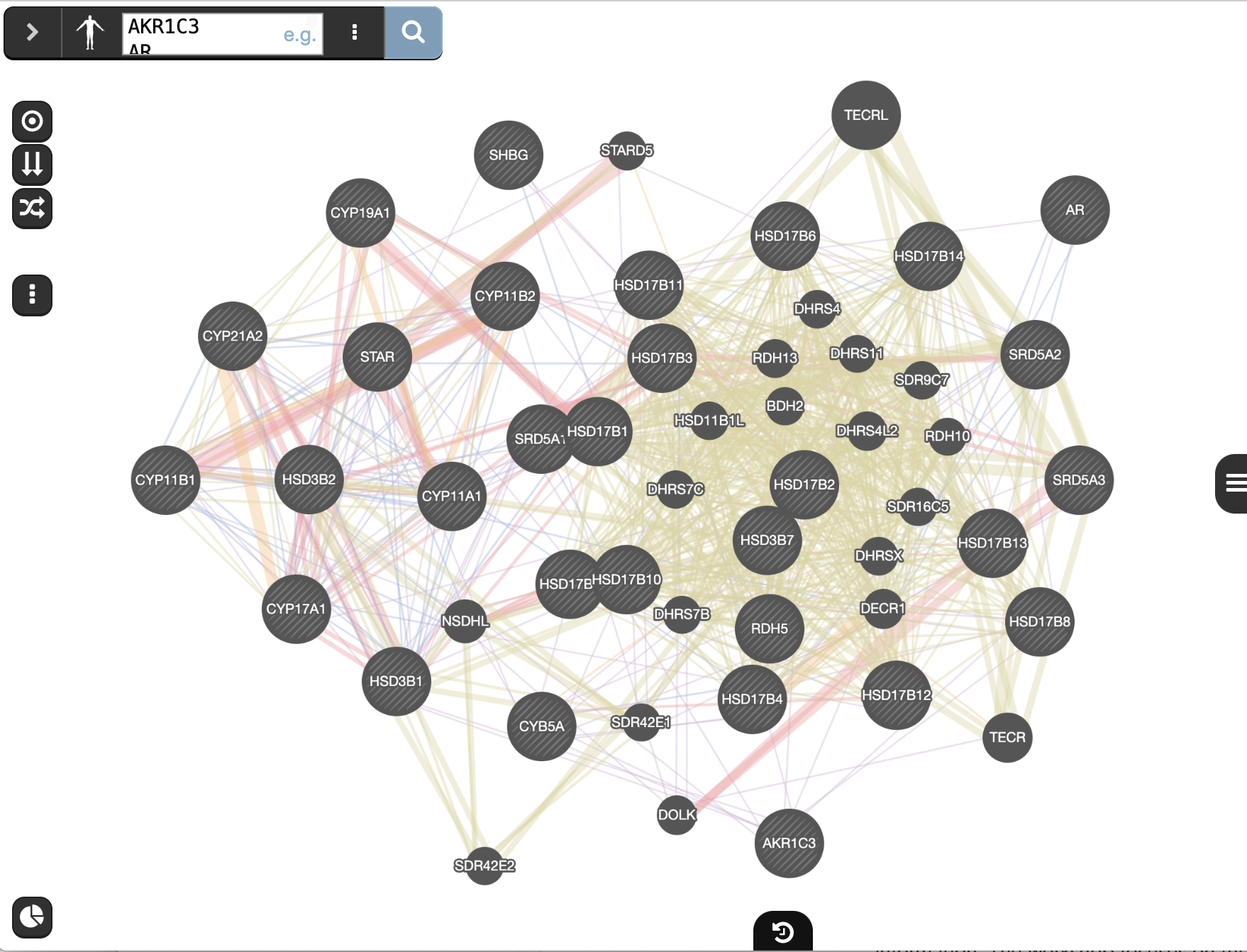
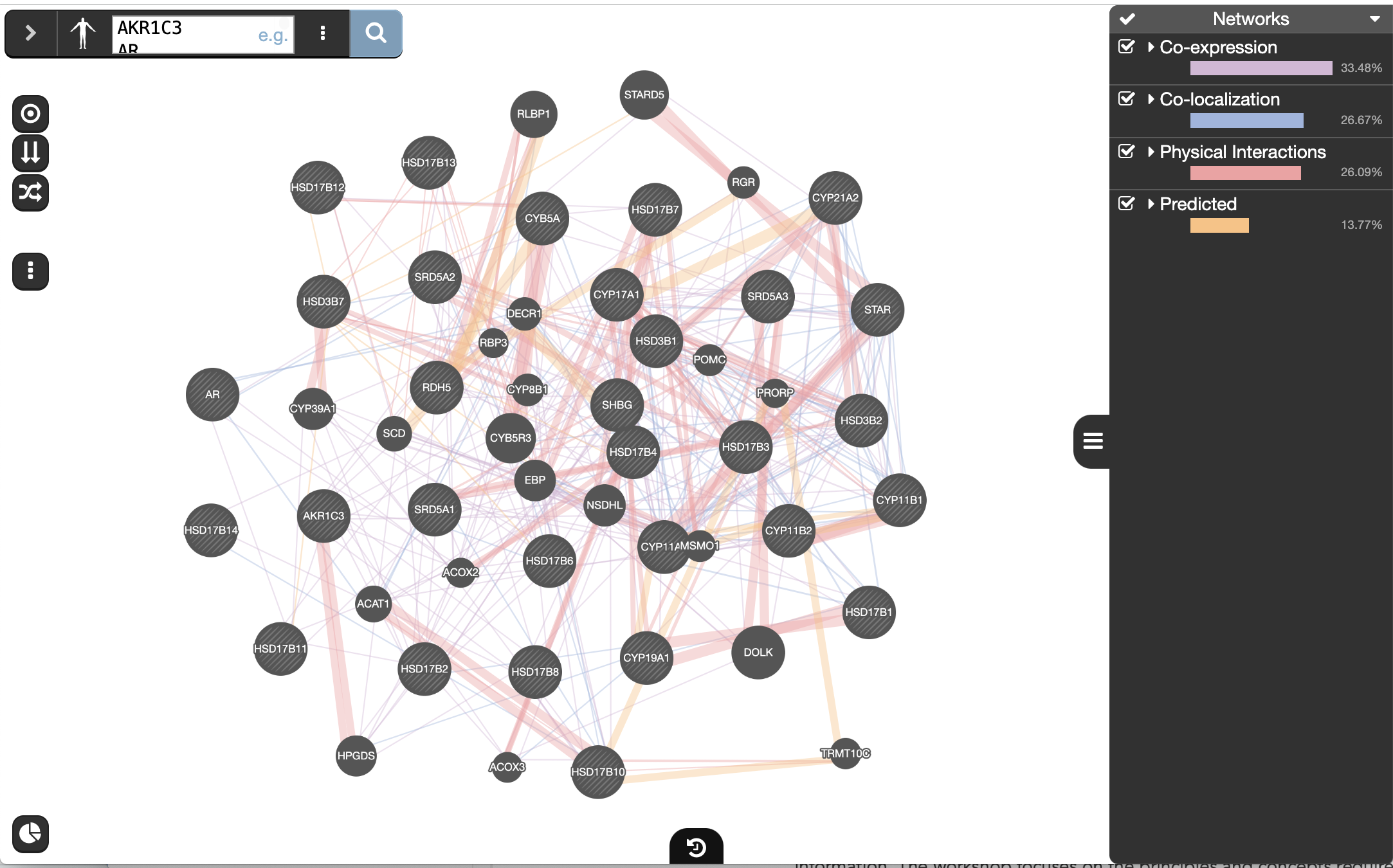
and wait for the results.When your search results load, examine the network.
- Genes you searched with are indicated with stripes,
- related genes added by GeneMANIA are represented in black,
- and colored links represent the interactions that connect the nodes (genes).
- Move nodes around by selecting them with a mouse to investigate how they are connected.
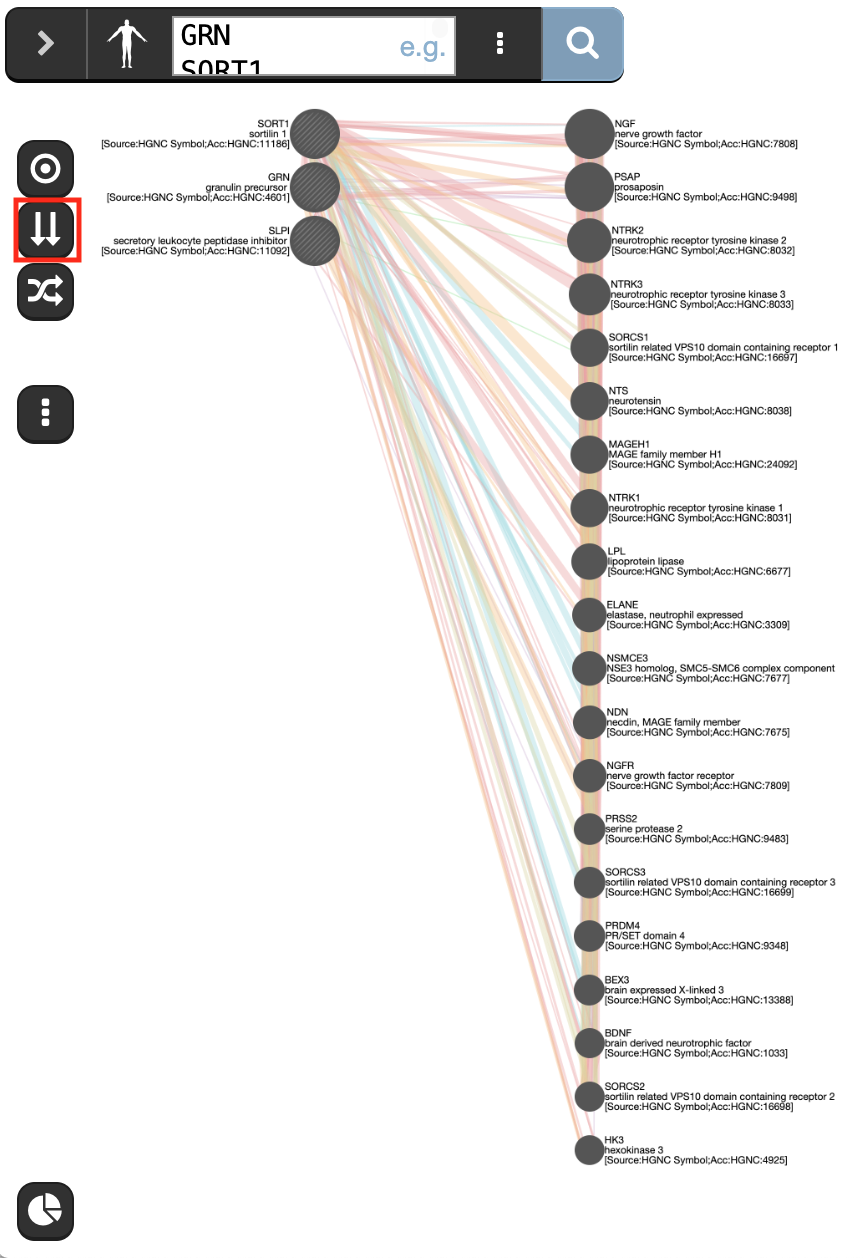
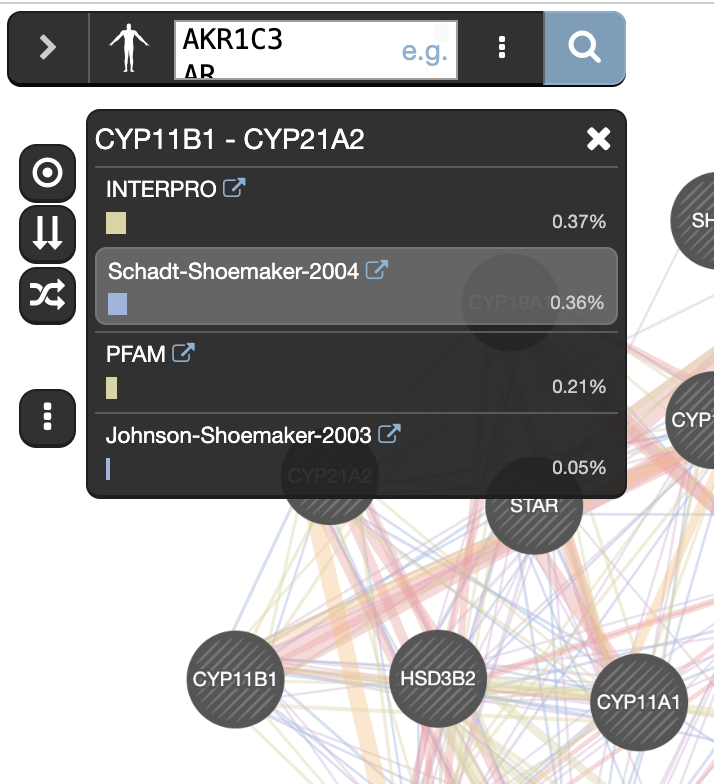
Click any link (edge) connecting two nodes to highlight information about it.
Clicking on an edge between 2 nodes will display information about all interaction networks that connect these 2 nodes. It indicates the reference (publication) for these interactions. The color indicates the type of interaction (co-expression, shared protein domains, co-localization, physical interactions and predicted).
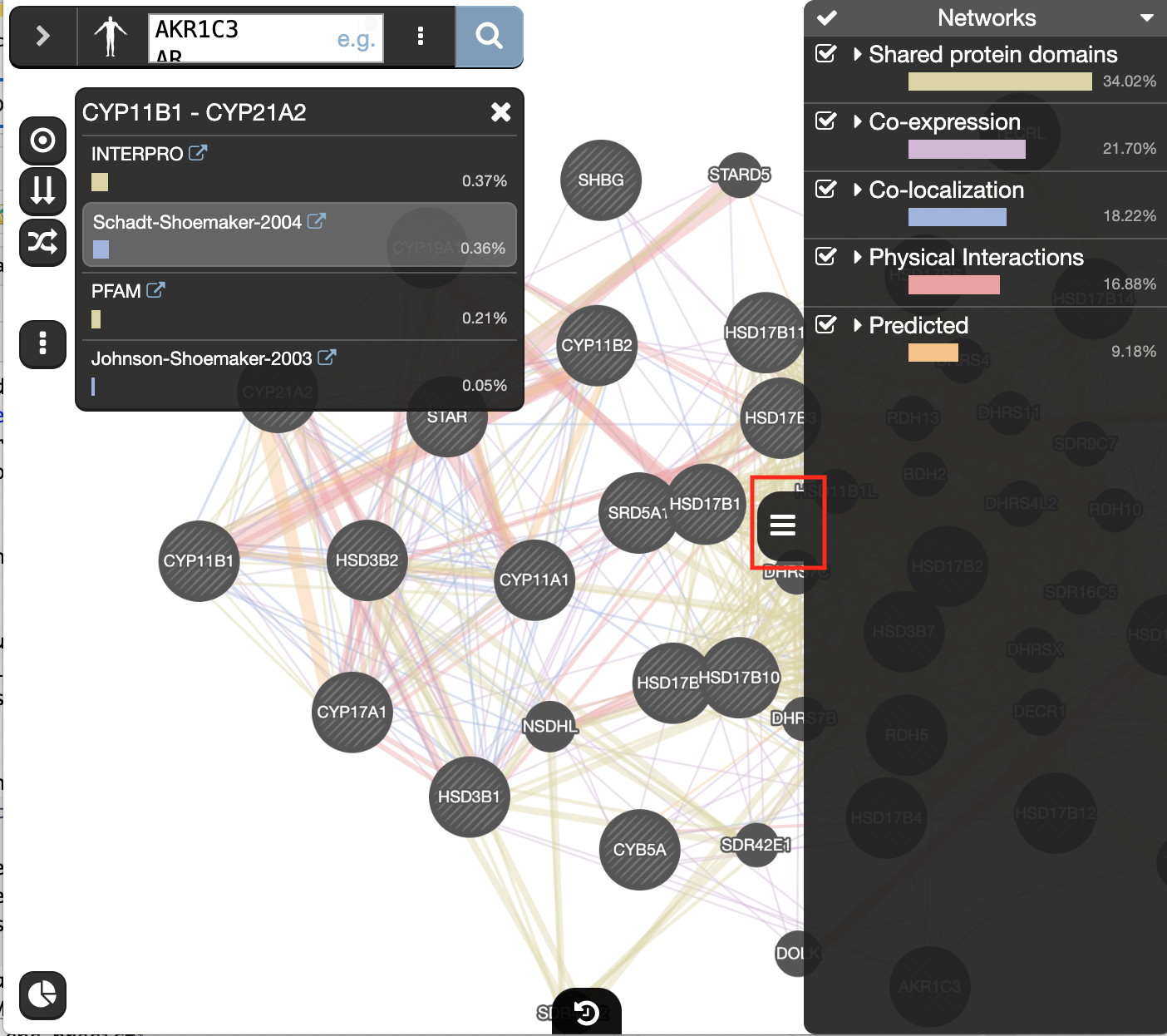
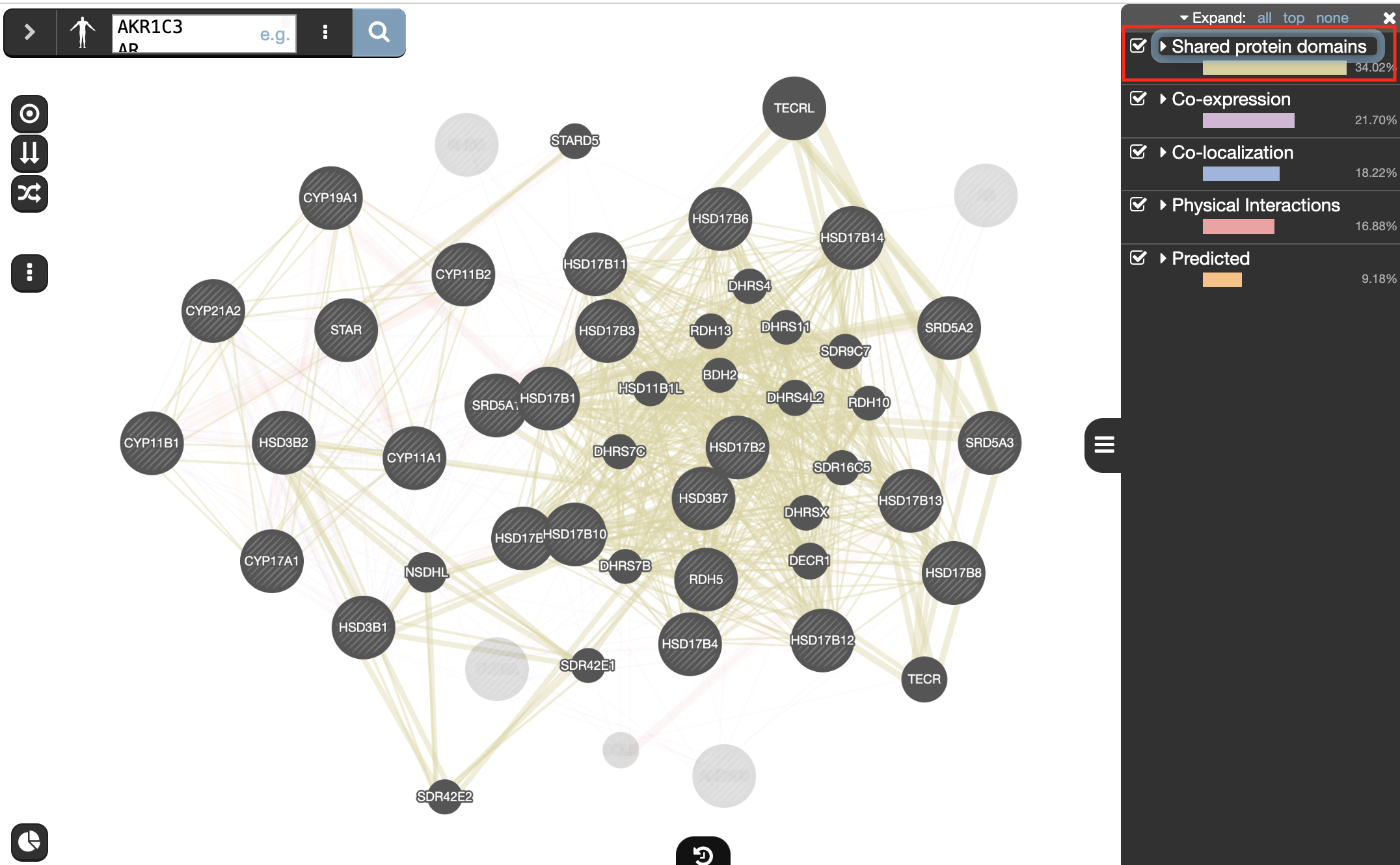
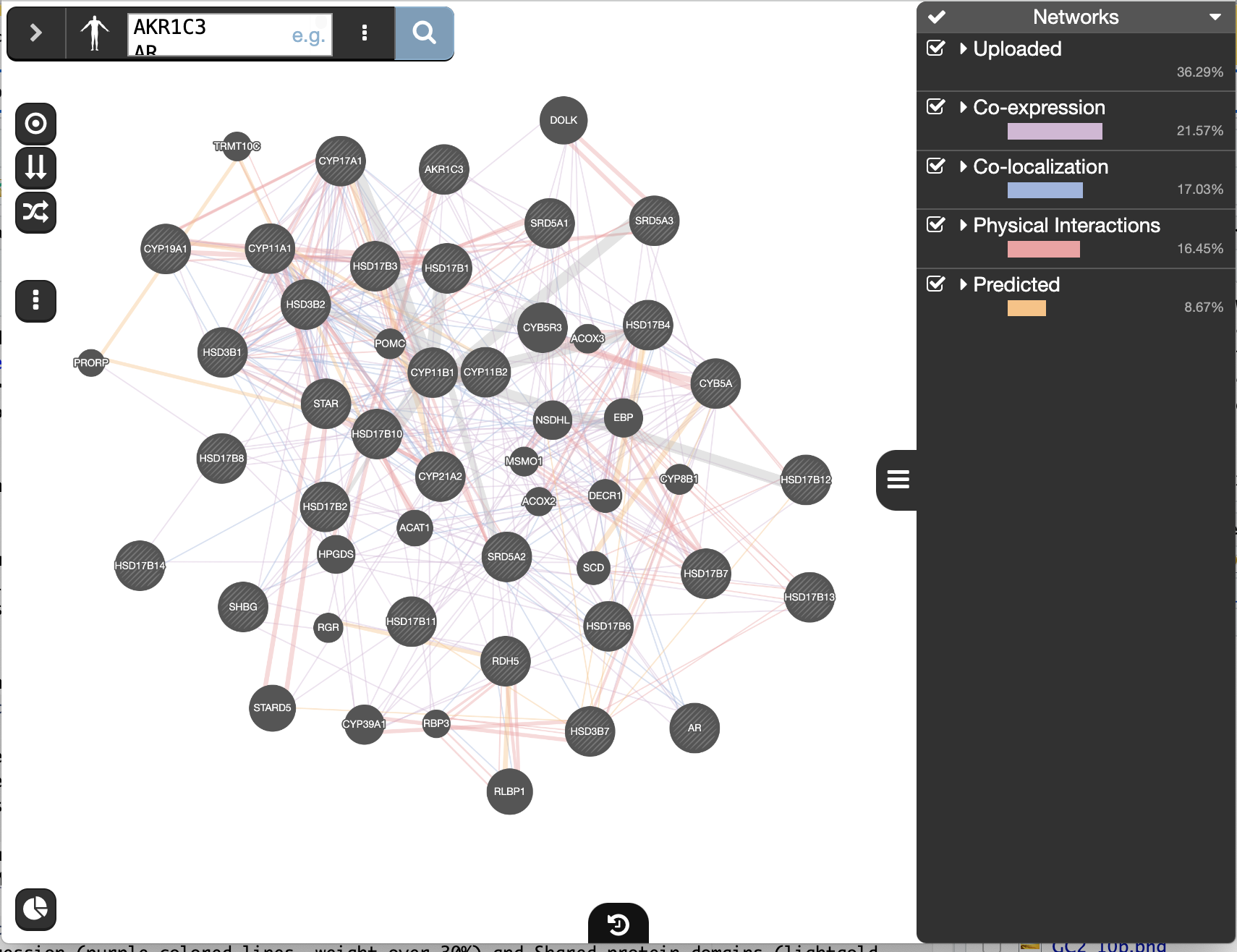
- Locate and expand the ‘Networks’ summary tab (on the right
 ) and look at what data has been used to create the network and predictions.
) and look at what data has been used to create the network and predictions.
Shared protein domains (lightgold colored lines, weight over 30%) and Co-expression (purple colored lines, weight over 20%) influence the results the most, but Co-localization (blue colored lines), Physical interactions (salmon colored lines) and Predicted (orange) data also contribute.
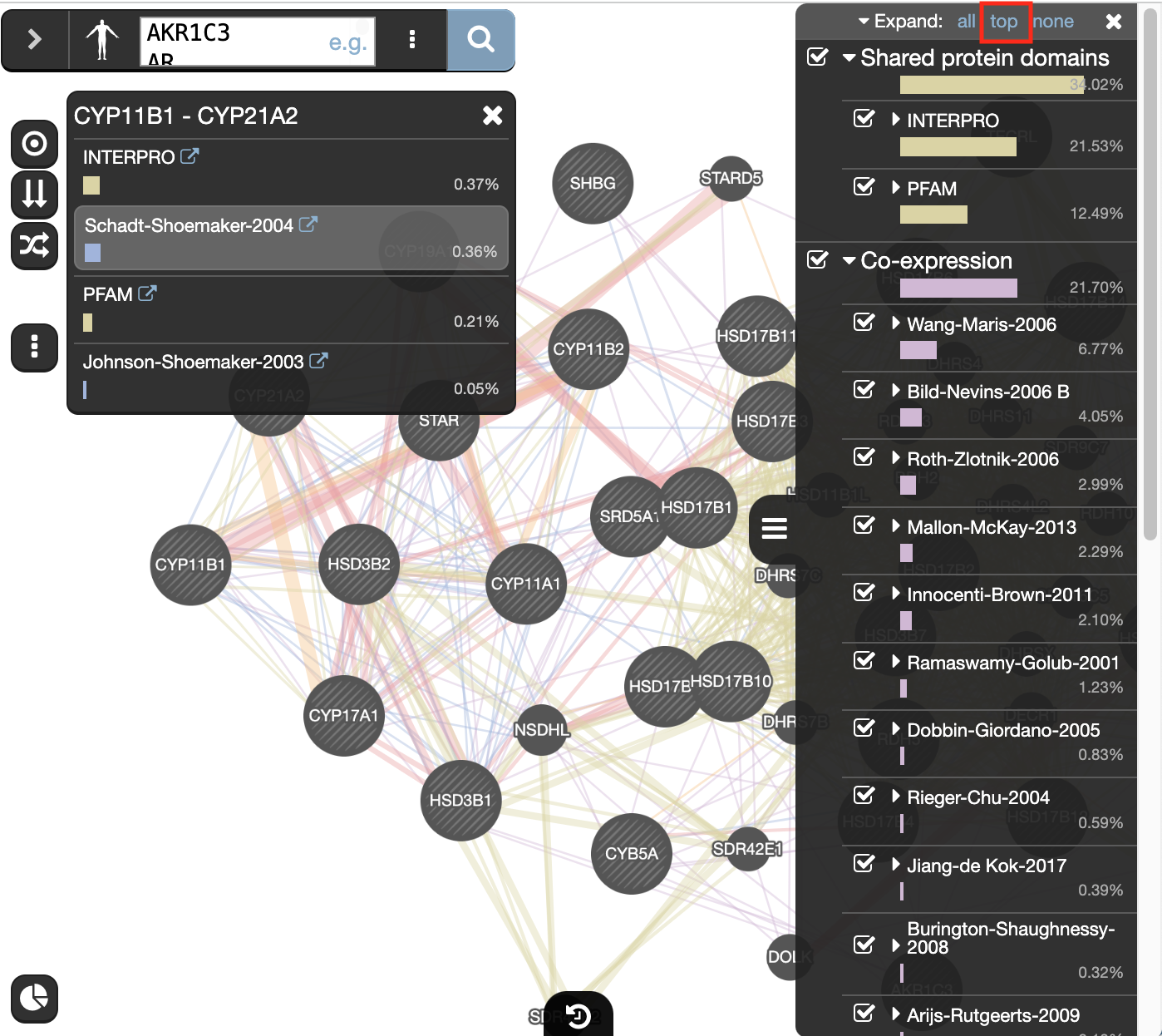
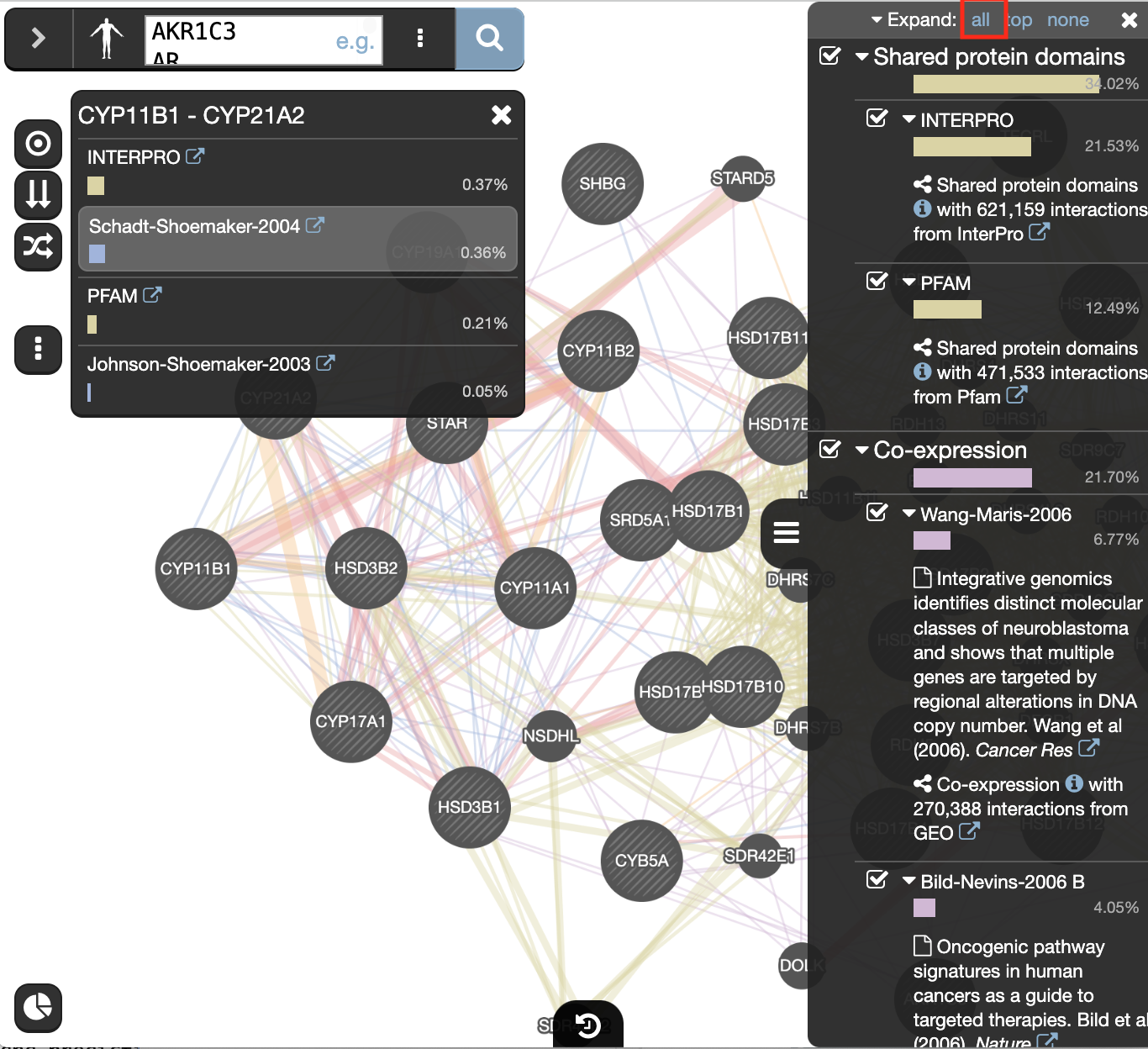
At the top of the Networks summary tab,
- click on the down arrow.
- try Expand “none”, then “top” and “all” to get information about the sources of the different networks.
- Highlight all connections corresponding to each network by clicking the name of each network category.
- Click on “Shared protein domains” and see which genes are connected by shared protein domains.
- You can do the same for “Co-localization” , “Co-expression” and “Physical interactions”.
Seeing or highlighting the number of connections for each data source makes it easier to understand why co-expression and shared protein domains have the highest percent weight for this network: * they connect more genes than physical interactions and predicted; * A higher weight means that this network contributes more to finding related genes.
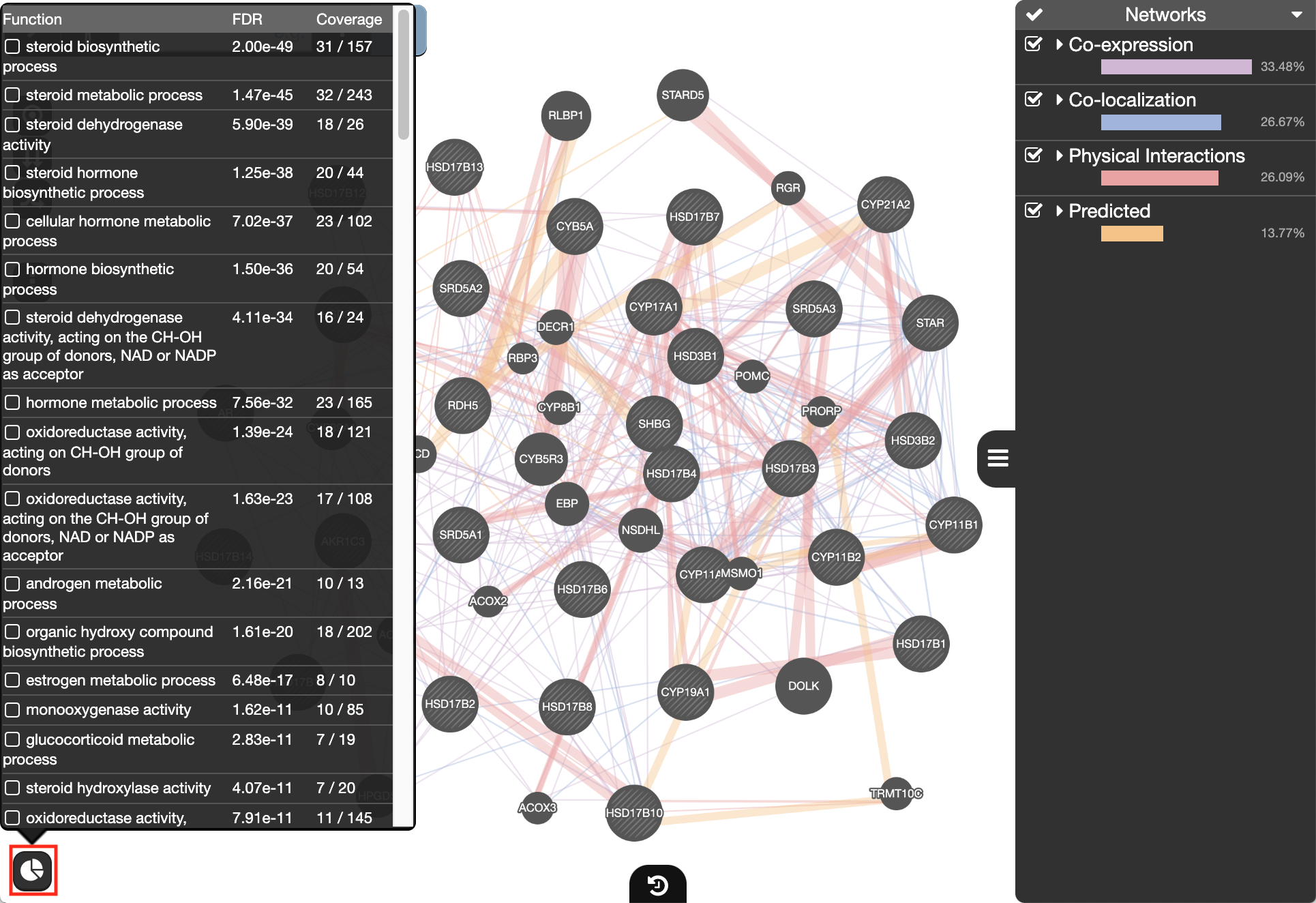
Locate the Functions summary tab (bottom left
) and look at what functions were significantly enriched in this list of prostate genes.“Shared protein domains” is an important part of this network. What would happen to the GeneMANIA results if we didn’t include this source when we run this GeneMANIA search?
- Click on ‘Show advanced option
 ’ which is located at the right of the search box.
’ which is located at the right of the search box. - Uncheck ‘Shared protein domains’ and
- click on the search icon .
- Explore the results.
- Click on ‘Show advanced option
Locate the Functions summary tab (bottom left
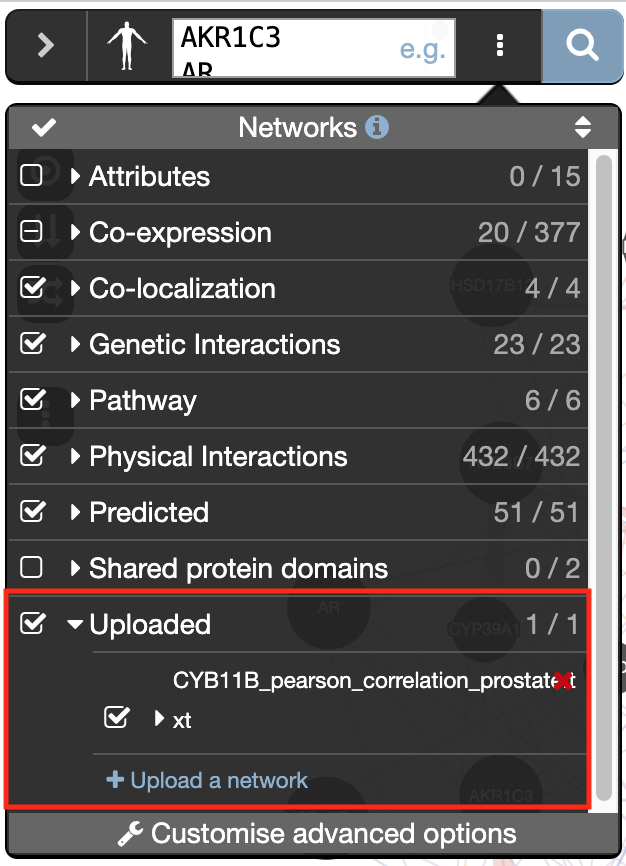
) and look at what functions were significantly enriched with these new settings.Upload a custom network to GeneMANIA:
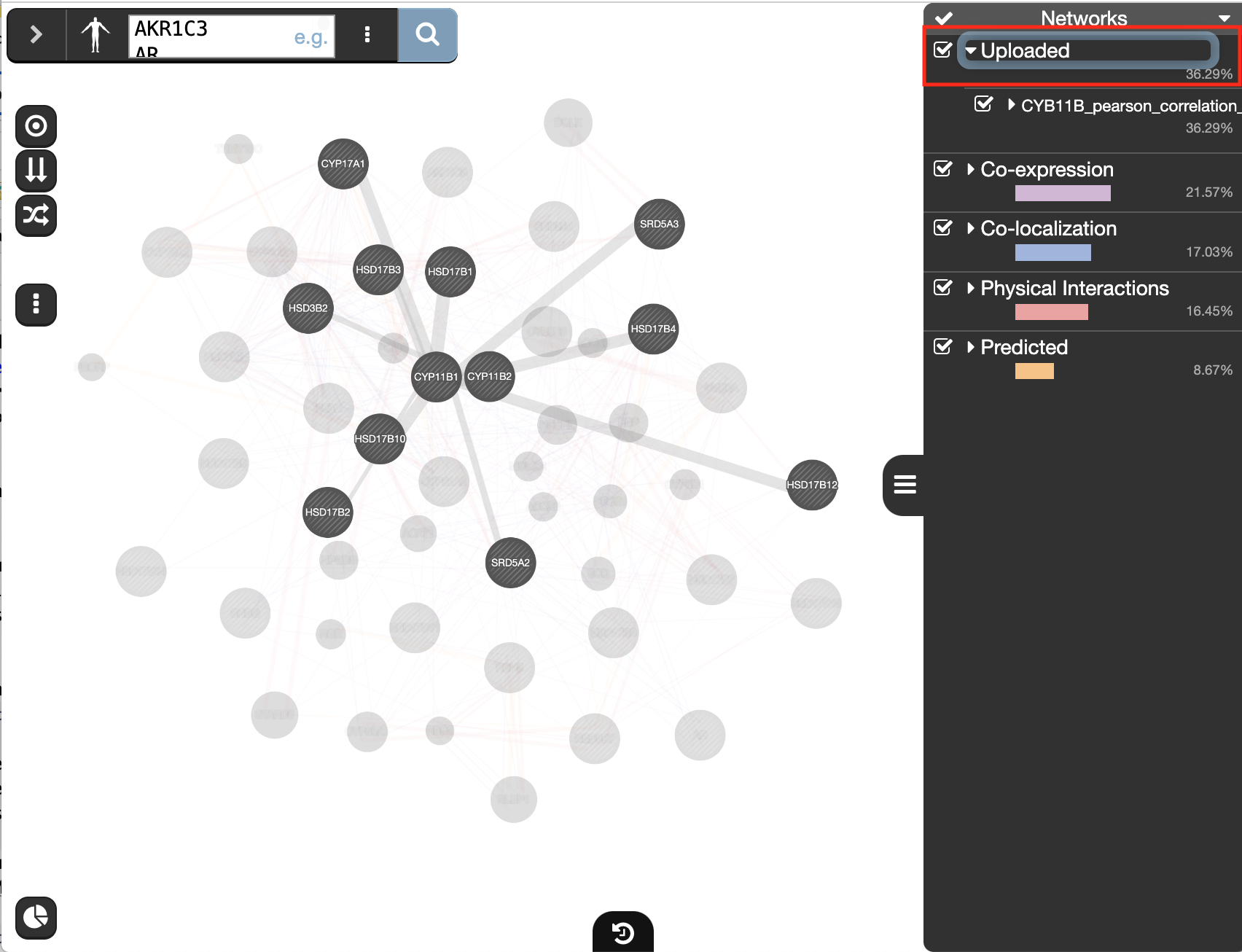
- Go to the menu option at the right of the search box (the icon with three dots) and
- at the bottom of the network list, locate Uploaded, expand this option using the down arrow
- click on “Upload a network” and browse your computer to locate and select the file CYP11B_pearson_correlation_prostate.txt.
- Wait about a minute for the network to be uploaded.
- Click on the search icon to launch the query
- explore the results and locate the genes linked by the custom network
click on “Uploaded” in the Networks tab on right hand side.
- Try additional parameters of the ‘Customise advanced options ’ tab and look at how the changes you made influenced the results. For example change ‘Network weighting’ method or ‘Max resultant genes:’.
EXERCISE 2 ANSWERS: DETAILED STEPS AND SCREENSHOTS
Exercise 2 - STEPS 1 to 4
Check that the parameter ‘Max resultant genes’ is set to ‘20’ and ‘Max resultant attribute’ to ‘10’
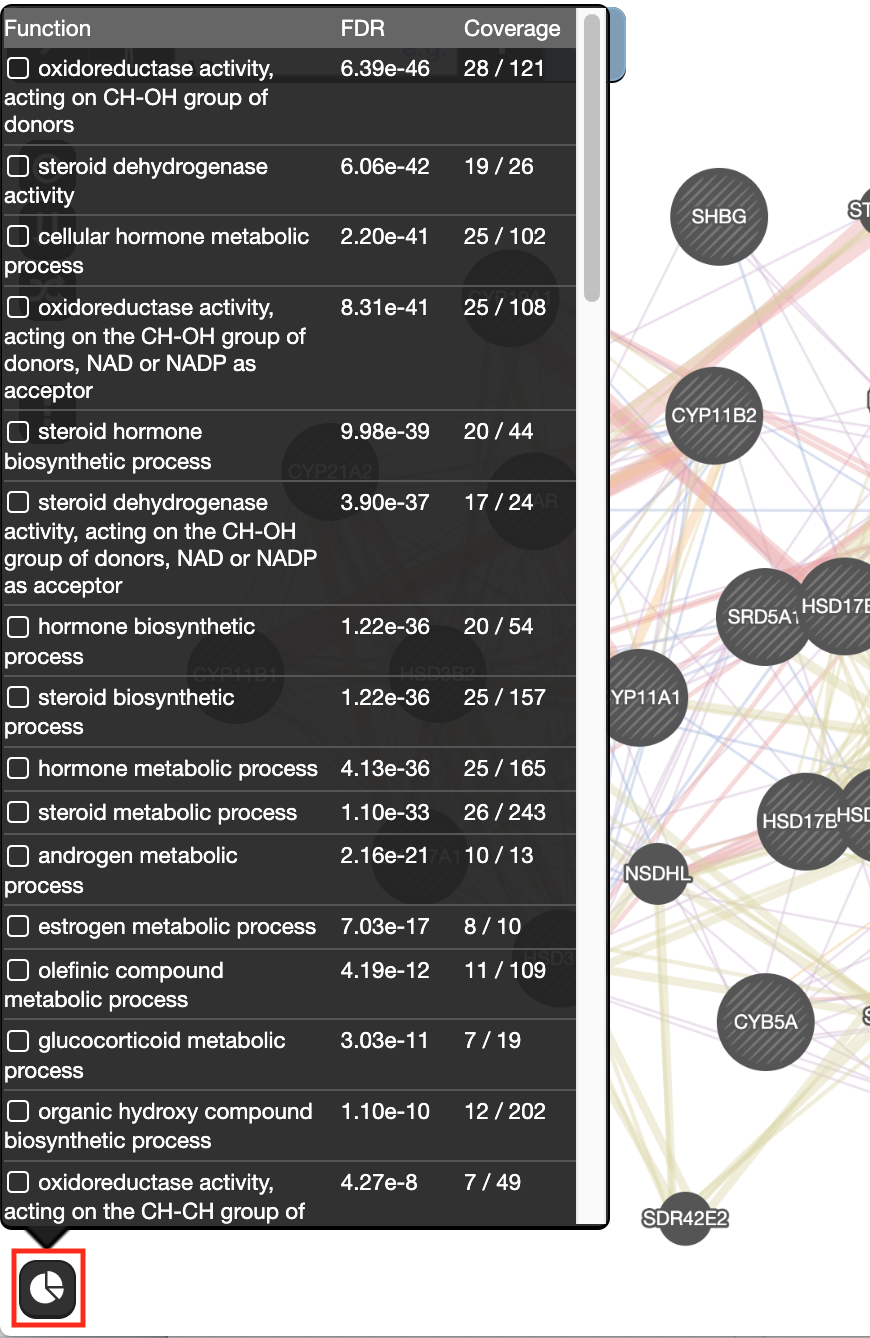
Exercise 2 - STEP 9
The top pathways with the strongest enrichments are: “oxidoreductase activity” with 28 genes in the list overlapping with this pathway. The FDR is equal to 6.39e-46.
Exercise 2 - STEP 10
Question “Shared protein domains” is an important part of the network. What would be the GeneMANIA results if we don’t include this source when we run the GeneMANIA search?
Answer If “shared protein domain” is removed, the relationships between the nodes are from the Co-expression, Co-localization, Predicted and Physical interactions networks.The genes added to the network are different compared to the first network created with “Shared protein domain”.
EXERCISE 3: QUESTIONS AND STEPS TO FOLLOW
To start this exercise, you need to download the Mixed_gene_list.txt file and save it on your computer.
For this exercise, you are working on a gene list created by combining 3 user defined gene lists available from the cBioportal (http://www.cbioportal.org). It contains genes implicated in the DNA damage response, the PI3K-AKT-mTOR signaling pathway and Folate transport. This list is representative of a gene list obtained from transcriptomics data. During this exercise, we will first characterize our gene list based on functions and then we will add potential drug and microRNAs targeting genes in the network, and we will save the report.
Skills:
- GeneMANIA search using a gene list;
- Navigating Search Results;
- Exploring Functions;
- Adding attributes;
- Create a report.
STEPS
Go to GeneMANIA’s homepage at http://www.genemania.org/.
In the search window,
- ensure that the model organism is set to Homo sapiens .
- ensure that your Uploaded network from the previous exercise is not selected. to delete it you can click on the red ‘x’ next to it.
- ensure that the model organism is set to Homo sapiens
Copy and paste genes in the file Mixed_gene_list.txt. Click on the search icon
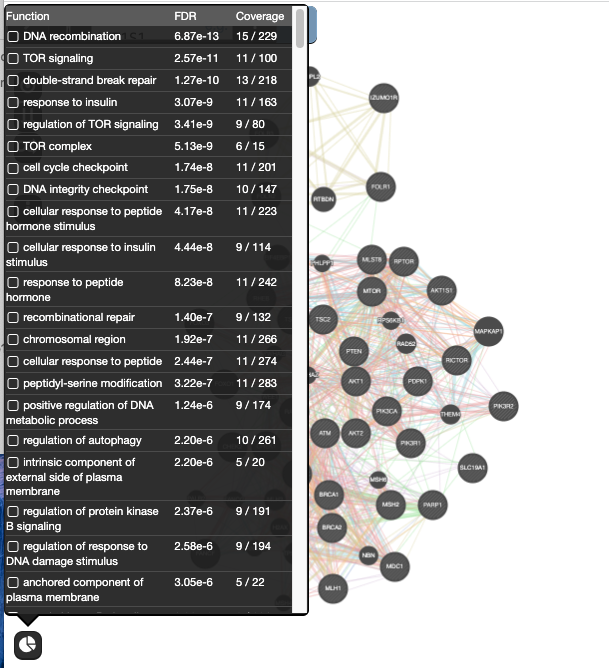
and wait for the results.Locate the Functions summary tab (bottom left
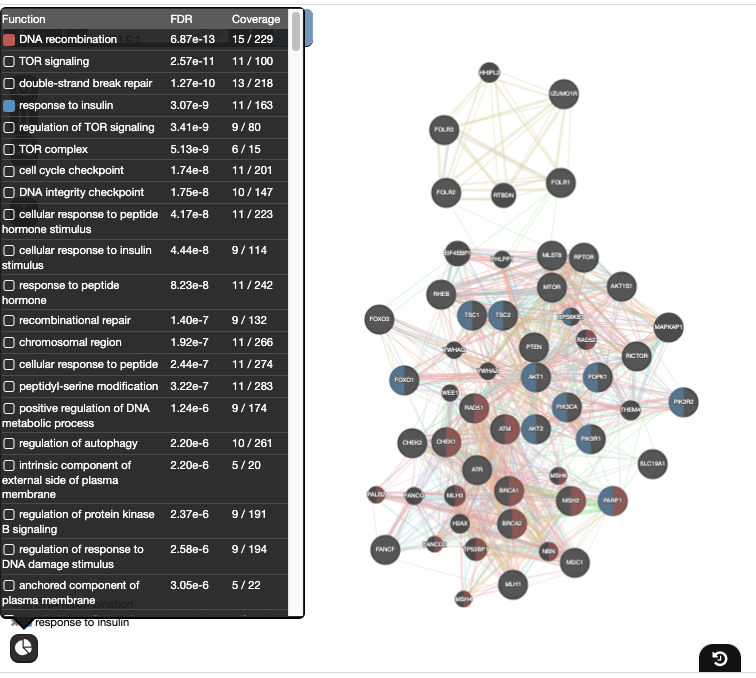
) and look at functions returned by GeneMANIAIn the functions summary tab, check some functions to color genes included in these functions. To follow this tutorial, you can for example color the “response to insulin” , “DNA recombination”
Next, we will add miRs and drug interaction networks.
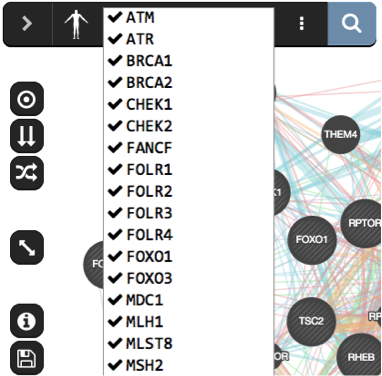
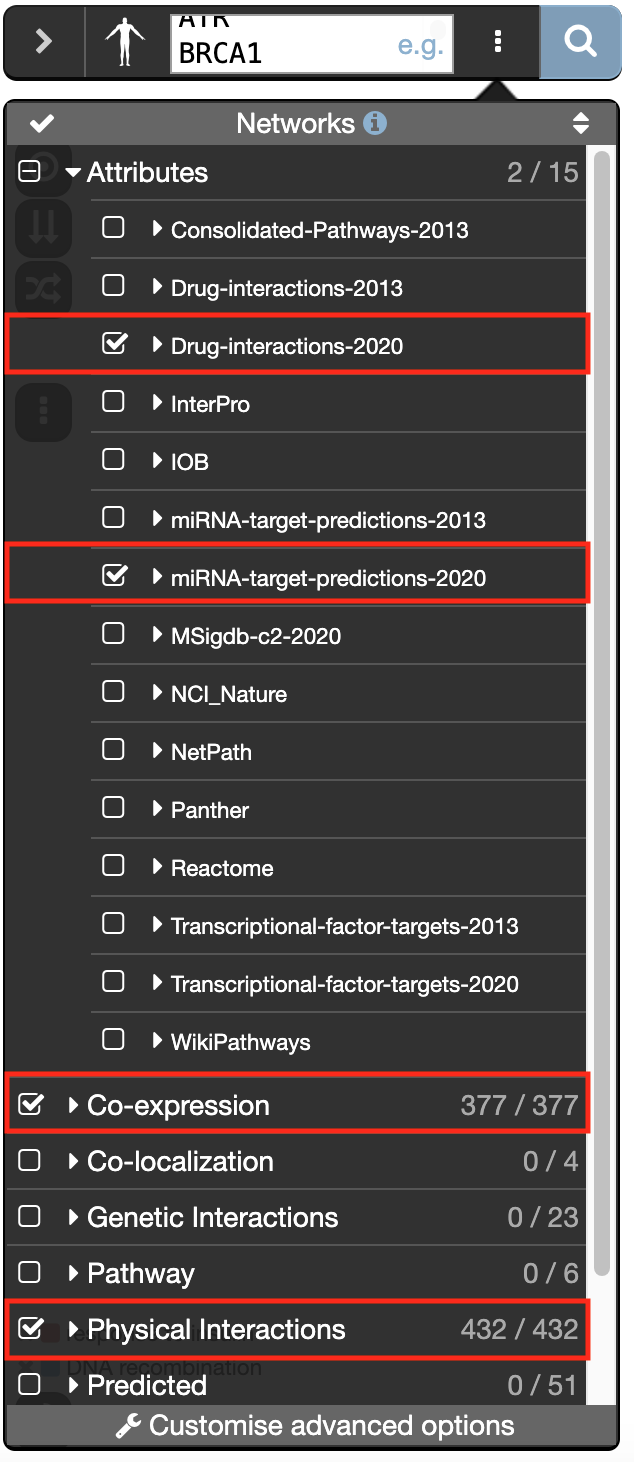
- Click on ‘Show advanced option ’ which is located at the right of the search box.
- In the ‘Networks’ tab, expand ‘Attributes’ and check “Drug-interactions-2020” and “miRNA-target-predictions-2020”.
- Check “Physical interactions” and “Co-expression” .
- Click on “Customise advanced options”. Set “Max resultant genes” to 20 and “Max resultant attributes” to 40.
- Click on the search icon and wait for the results. Explore the network.
- Click on ‘Show advanced option
Drug-interactions and miRNA-target-predictions nodes are displayed in gray. The nodes connected to a drug are genes that are targeted by that drug and nodes connected to a microRNA (miR) are genes predicted to be targeted by that miR.
Locate our favorite gene PDPK1 in the network,
- select it by moving the mouse cursor to its node and wait there for a second. (you can also, click and hold on the node)
- This will highlight this gene and all its connections.
Generate and save a report of your results by locating the save menu
, and selecting “Report”. The PDF report provides a detailed description of your search and results.Investigate the “history” function by clicking on the related icon
 located at the bottom of the window. A panel pops up showing the past networks generated by GeneMANIA. Clicking on one panel will relaunch the search for this network.
located at the bottom of the window. A panel pops up showing the past networks generated by GeneMANIA. Clicking on one panel will relaunch the search for this network.

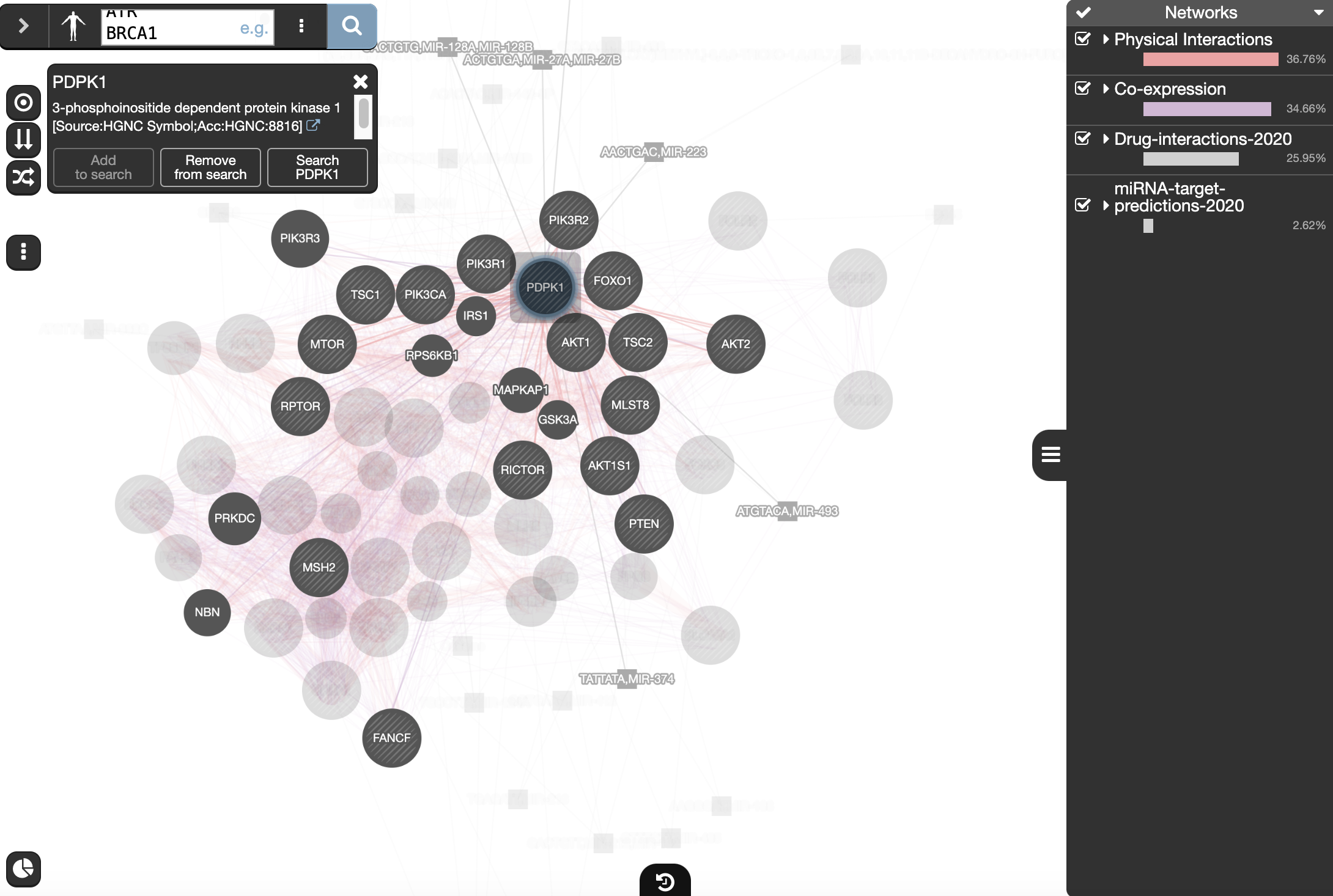
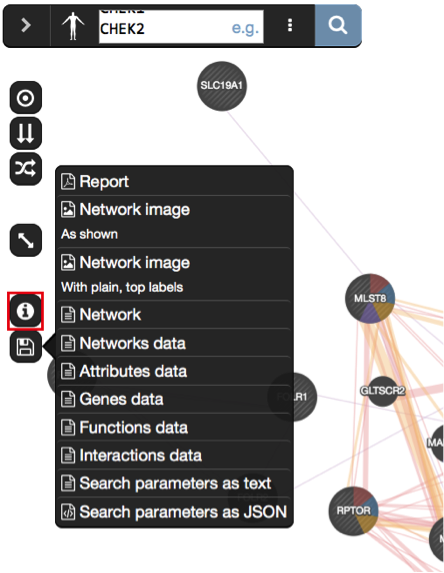
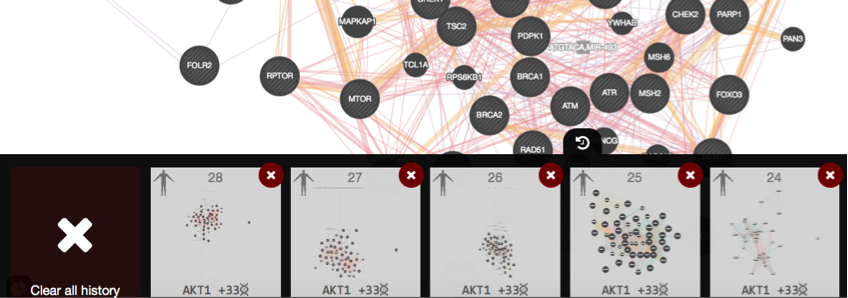
SOME DEFINITIONS:
What are the networks: Definition of the types of interaction:
Shared domains: Protein domain data. Two gene products are linked if they have the same protein domain. These data are collected from domain databases, such as InterPro, SMART and Pfam.
Co-localization: Genes expressed in the same tissue, or proteins found in the same location. Two genes are linked if they are both expressed in the same tissue or if their gene products are both identified in the same cellular location.
Co-expression: Gene expression data. Two genes are linked if their expression levels are similar across conditions in a gene expression study. Most of these data are collected from the Gene Expression Omnibus (GEO); we only collect data associated with a publication.
Predicted: Predicted functional relationships between genes, often protein interactions. A major source of predicted data is mapping known functional relationships from another organism via orthology.
What is defined by evidence sources?:
- Evidence sources are the information contained in the multiple databases that GeneMANIA uses to establish interaction between two genes.
Network:
Node : circle representing the genes
Edge: line that links two nodes and represent an interaction between two genes (multiple lines correspond to multiple sources
Node size: Mapped to gene score, i.e. the degree to which GeneMANIA predicts the genes are related
Thickness of edge: Strength/weight of interaction
Layout : The layout is different each time so the user can request the layout run multiple times until the user is satisfied with the result.
in Networks tab:
- Percent weight (score) : a higher weight means that this network helped more to find related genes.
in Functions tab :
FDR : False discovery rate (FDR) is greater than or equal to the probability that this is a false positive.
Coverage : (number of genes in the network with a given function) / (all genes in the genome with the function)
In advanced options:
Network weighting? GeneMANIA can use a few different methods to weight networks when combining all networks to form the final composite network that results from a search. The default settings are usually appropriate, but you can choose a weighting method in the advanced option panel. (more details at http://pages.genemania.org/help/).
Related genes : are genes added by GeneMANIA in addition to the genes from the query. It helps to grow the network and then to predict function of the query gene(s).
The attributes represent the differences sources of evidence that can be used to build the network.
Notes :
prostate cancer gene list is “AKR1C3 AR CYB5A CYP11A1 CYP11B1 CYP11B2 CYP17A1 CYP19A1 CYP21A2 HSD17B1 HSD17B10 HSD17B11 HSD17B12 HSD17B13 HSD17B14 HSD17B2 HSD17B3 HSD17B4 HSD17B6 HSD17B7 HSD17B8 HSD3B1 HSD3B2 HSD3B7 RDH5 SHBG SRD5A1 SRD5A3 STAR”.
mixed gene list is AKT1 AKT1S1 AKT2 ATM ATR BRCA1 BRCA2 CHEK1 CHEK2 FANCF FOLR1 FOLR2 FOLR3 FOXO1 FOXO3 MDC1 MLH1 MLST8 MSH2 MTOR PARP1 PDPK1 PIK3CA PIK3R1 PIK3R2 PTEN RAD51 RHEB RICTOR RPTOR SLC19A1 TSC1 TSC2
look at GeneMANIA help pages when you run an analysis on your own after the workshop: http://pages.genemania.org/help/.